内存 100%排查及常见案例
目录
一、内存100% 排查过程
1.老规矩top命令 查看cpu和内存情况
我们JVM设置的最大堆内存是800M,虚拟机内存是3G,这里看到内存已经爆了,随之带来的则是频繁FULL GC导致的CPU 100%

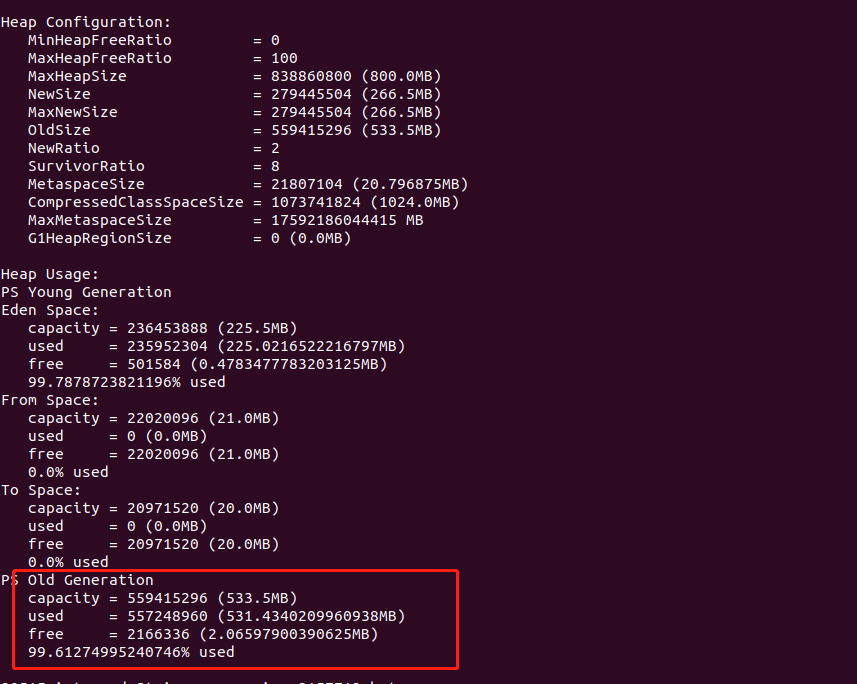
2.jmap -heap PID 查看JVM内存使用情况
可以看到老年代的使用率已经100%了
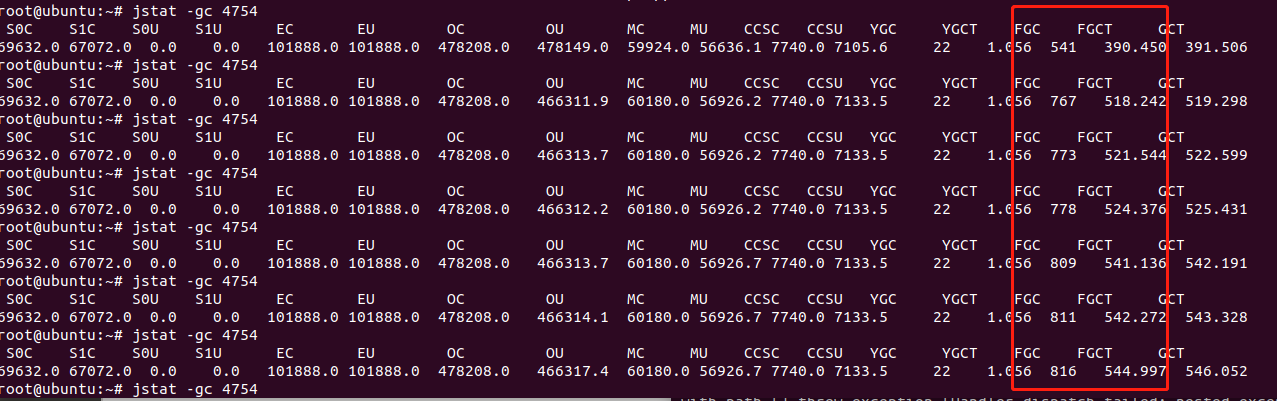
3.jstat -gc PID查看GC的情况
- YGC : YG GC的次数
- YGCT:YG GC的平均时间
- FGC: FULL GC的次数
- FGCT:FULL GC的平均时间
这里连续的几次查看,可以看到FULL GC的次数在疯狂的增长,而且FULL GC的平均时间也在增长,这就是CPU 100%的原因,因为FULL GC会导致stop-the-world的发生
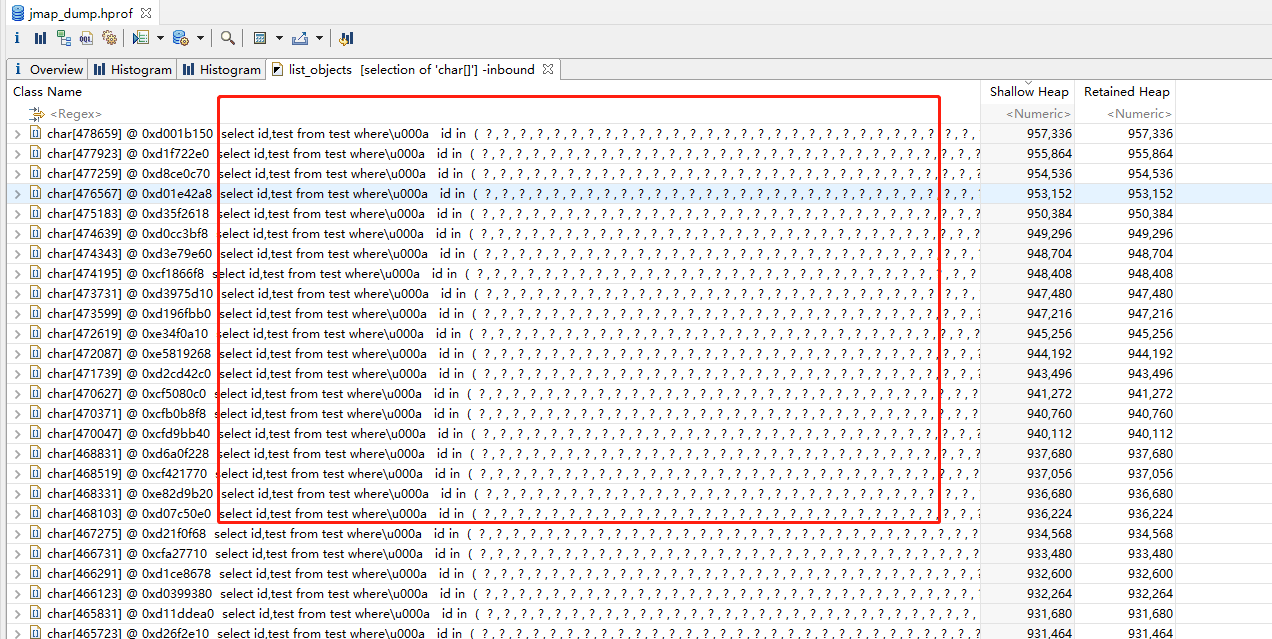
4.jmap -dump:format=b,file=./jmap_dump.hprof PID 使用jmap命令生成分析所需要用的dump文件,用Eclipse Memory Analyzer 工具打开
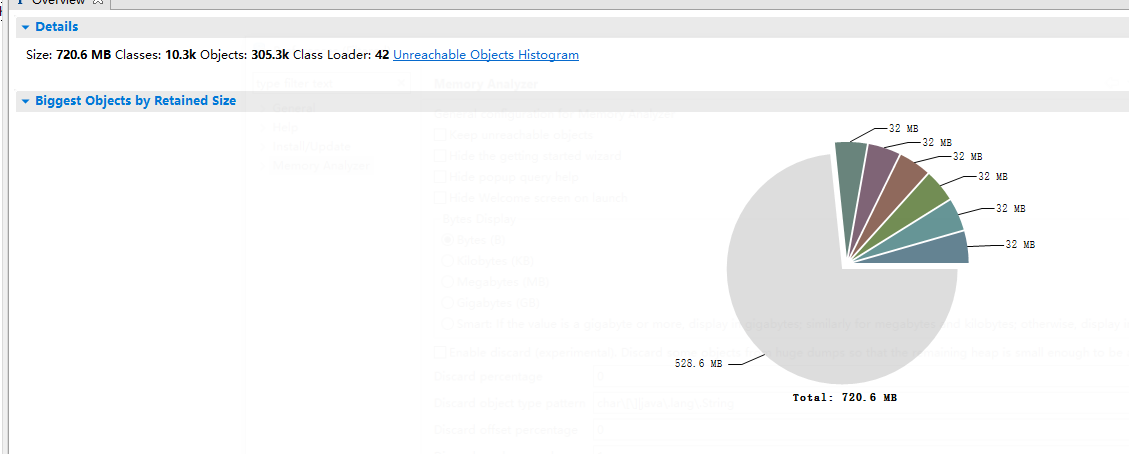
查看占用最大的类
查看被谁引用了, 因为这个工具默认加载的就是不可被回收的对象,所以可以明显的看到具体的问题出在哪了
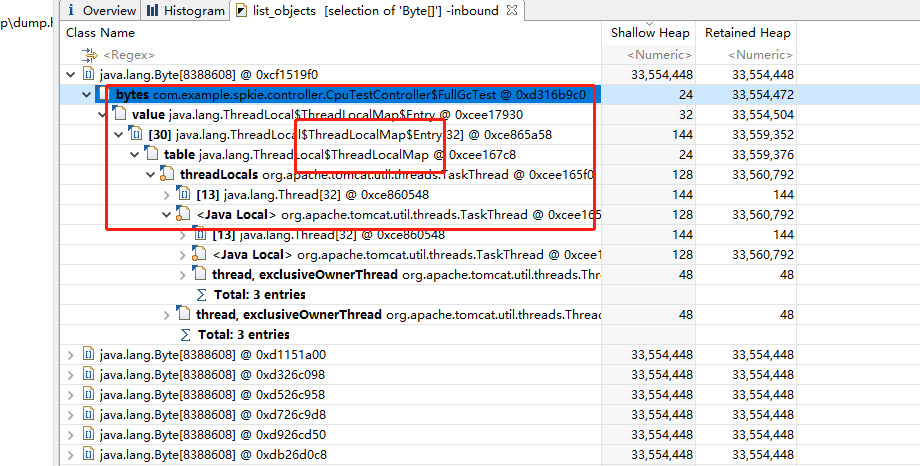
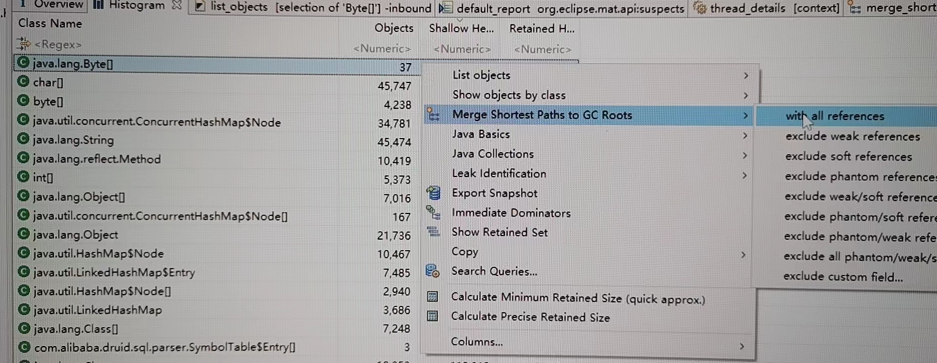
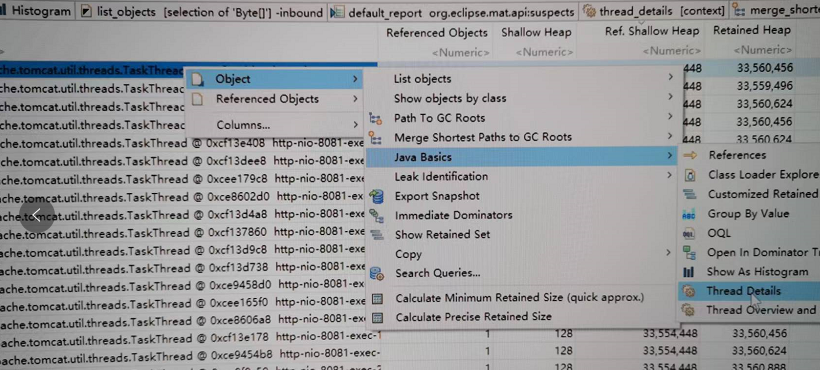
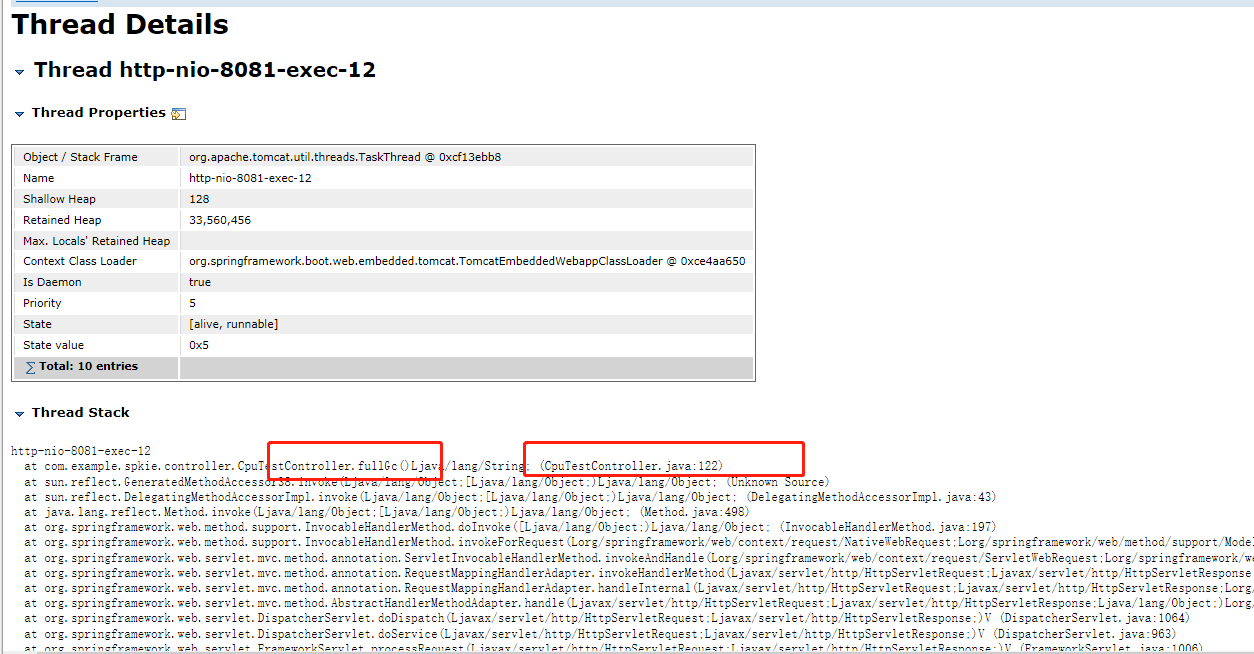
还可以换一种方式,就是如果是外部请求导致的,可以直接查看线程信息
二、测试案例
1.常见的TreadLocal内存溢出
使用jmeter工具并发请求 结果见上面排查结果
private static ThreadLocal<FullGcTest> threadLocal=new ThreadLocal();
/**
* ThreadLocal内存溢出 测试
* @return
*/
@GetMapping("/fullGc")
public String fullGc(){
for (int a = 0; a < 5; a++) {
//一次性产生5个8m 对象
threadLocal.set(new FullGcTest(new Byte[1024*1024*8]));
}
return "Success";
}
2. Druid连接池SQL监控 导致的内存溢出
Druid在打开SQL监控后,会将执行的SQL语句保存下来,在一个LinkHashMap里面,以SQL语句为Key长期持有,默认情况下会保存1000条,这部分对象是不会被回收掉的,这里模拟极端情况,也就是这里每条SQL语句都非常大,可以通过控制随机数的大小来控制SQL语句的大小(根据JVM堆内存动态设置)
使用jmeter工具并发请求
/**
* druid测试 需要加入Druid连接池 并打开SQL监控
* @return
*/
@GetMapping("/druidTest")
public String druidTest(){
List<Integer> ids=new ArrayList<>();
int i1 = new Random().nextInt(20000) + 500000;
for(int i=0;i<i1;i++){
// 产生500000 - 520000个id
ids.add(new Random().nextInt(900000)+100000);
}
testMapper.testSelect(ids.toArray(new Integer[0]));
return "OK";
}
使用并发测试后就会发现内存溢出 (前提是设置的JVM内存大小适合,如果JVM内存非常大,这里SQL语句可能会撑不爆,便不会发生内存溢出,但此时也可以导出dump查看不可回收对象)