线程池介绍
目录
- 1.Executor结构
- 2.ThreadPoolExecutor
- 3.ScheduledThreadPoolExecutor
- 4.线程池五种状态
- 5.线程池内线程如何复用?
- 6.线程池内线程退出处理
- 7.线程池使用注意事项及技巧
1.Executor结构
Executor、Executors、ExecutorService是不是傻傻分不清?
- Executor:最底层的接口,它将任务的提交和任务的执行分离开来
- ExecutorService:同样是一个接口,继承于Executor
- Executors:等于是线程池的工厂类,常见的ThreadPoolExecutor线程池就可以由它创建
2.ThreadPoolExecutor
常用构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
参数介绍:
- corePool:核心线程池大小。一般来说任务比较耗时可以配 CPU核数*2因为这样可以充分利用CPU,任务小而快则可以配 CPU核数+1甚至更小,因为线程上下文切换耗时(以上配置仅做参考,以实际场景为准 。获取CPU核心数:Runtime.getRuntime().availableProcessors())
- maximumPoolSize:最大线程池大小。当线程数>=corePoolSize,且任务队列已满时。线程池会创建新线程来处理任务,总线程数≤maximumPoolSize
- keepAliveTime:空闲时间,超过核心线程数的线程在空闲时间达到后会被注销
- TimeUnit:时间单位
- BlockingQueue:用来暂时保存任务的队列(阻塞队列)
- ThreadFactory:自定义的线程工厂,默认是一个新的、非守护线程并且不包含特殊的配置信息,我们也可以自定义加入我们的调试信息,比如线程名称、错误日志等等
- RejectedExecutionHandler:饱和策略。当线程数=maxPoolSize,且任务队列已满时,多余的任务需要采取的措施,有以下几种(默认AbortPolicy):
- AbortPolicy:丢弃任务并抛出RejectedExecutionException异常
- DiscardPolicy: 丢掉这个任务并且不会有任何异常
- DiscardOldestPolicy:丢弃最老的。也就是说如果队列满了,会将最早进入队列的任务删掉腾出空间,再尝试加入队列
- CallerRunsPolicy:主线程会自己去执行该任务,不会等待线程池中的线程去执行
- 自定义:当然也可以自定义策略啦
三种类型的ThreadPoolExecutor:
- FixedThreadPool:可重用固定线程数的线程池
- SingleThreadExecutor:单个线程的线程池(只有一个工作线程)
- CachedThreadPool:根据需要创建新线程的线程池
下面我们分别看一下这三种ThreadPoolExecutor
FixedThreadPool
源代码如下:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
其中corePool和maximumPoolSize 都被设置成指定的参数,而keepAliveTime设置为0L,意味着多余的空闲线程会被立即终止
运行示意图如下:
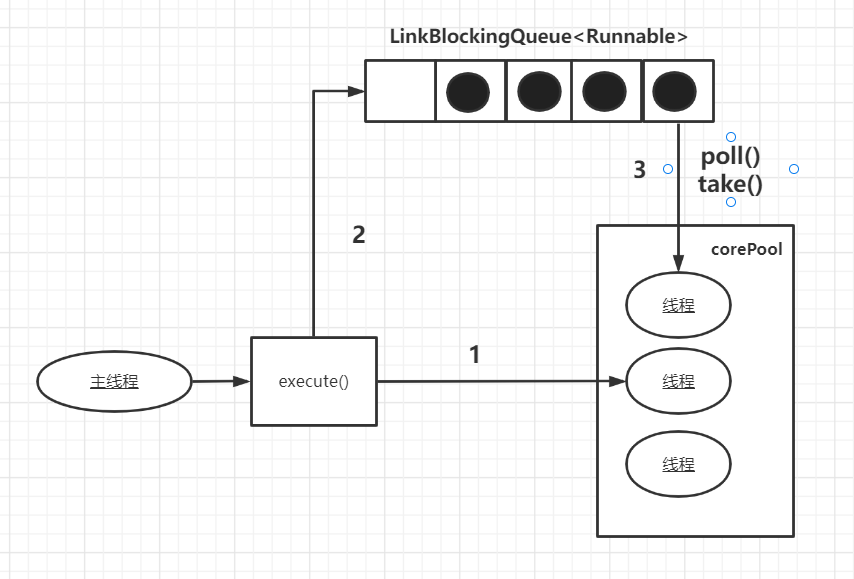
- 如果当前线程少于corePool,则创建新线程来执行任务
- 当运行的线程数等于corePool之后,将任务加入LinkedBlockingQueue队里
- 线程执行完手中任务会循环反复从LinkedBlockingQueue获取任务来执行
因为是LinkedBlockingQueue无界队列(长度Integer.MAX_VALUE),会有如下影响:
- maximumPoolSize和 keepAliveTime参数将会无效,因为maximumPoolSize=corePool
- 不会拒绝任务,因为是无界队列,任务不会满
SingleThreadExecutor
特点: 使用单个线程的Executor,源代码如下:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
其中corePool和maximumPoolSize 都被设置成了1,其他参数与FixedThreadPool相同
示意图如下:
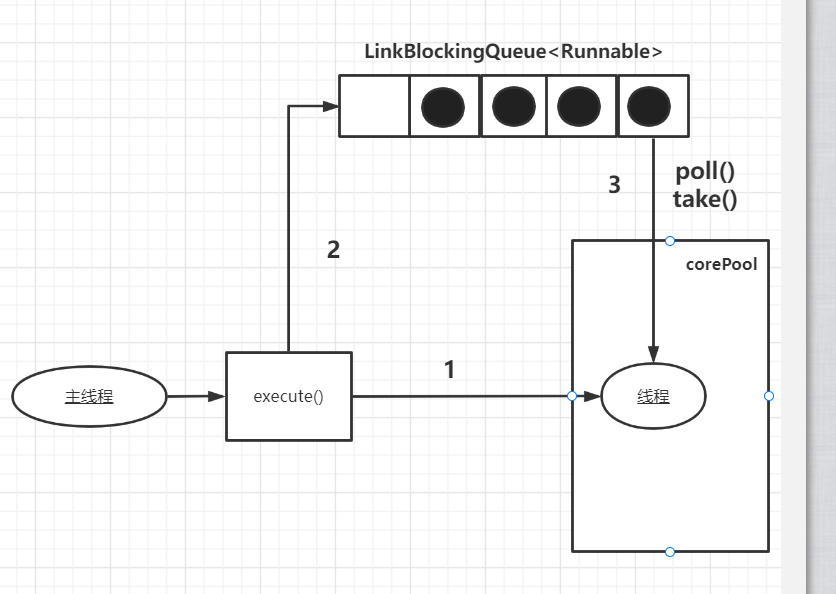
影响和运行方式都与FixedThreadPool相同,这里就不再赘述
CachedThreadPool
源代码如下:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
可以看到核心线程数为0,而最大线程池容量却是MAX,这意味着没有空闲线程就会不断的创建线程去执行,极端情况会耗尽CPU和内存资源,相反由于60s后空闲线程会被终止,所以长时间内保持空闲的情况下不会占用任何资源
SynchronousQueue是一个没有容量的阻塞队列,每一个插入操作都会等待另一个线程对应的取出操作
示意图如下:
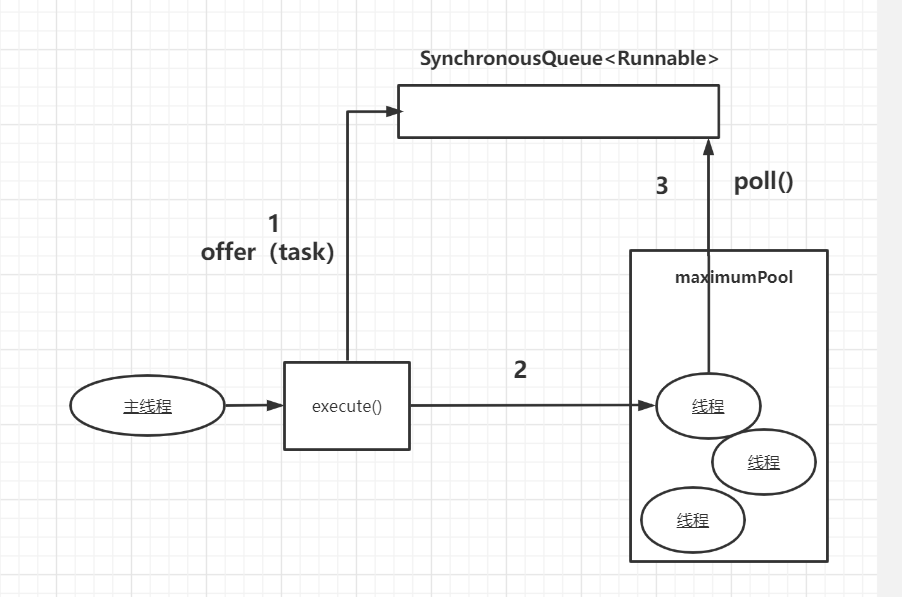
- 首先执行SynchronousQueue.offer,如果当前有空闲线程在执行SynchronousQueue.poll,则将该task任务交给此线程执行
- 当初始maximumPool为空,或者maximumPool没有空闲线程时,就没有线程执行SynchronousQueue.poll,此时就会创建一个新的线程来执行任务
- 线程执行完任务后将空闲60s,这期间会执行SynchronousQueue.poll,这60s内有新的任务就会执行,否则这个新线程就会被终止
扩展ThreadPoolExecutor
ThreadPoolExecutor是可扩展的,它提供了几个可以在子类中改写的方法:beforeExecute、afterExecute、terminated。在执行任务的线程中将调用这些方法,我们可以在这些方法内添加日志、计时、监视或统计信息收集的功能。如下:
public class MyThreadPoolExecutor extends ThreadPoolExecutor {
public MyThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
public MyThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory);
}
public MyThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, handler);
}
public MyThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
System.out.println("任务执行前");
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
System.out.println("任务执行后");
}
@Override
protected void terminated() {
System.out.println("线程池关闭的时候");
super.terminated();
}
}
3.ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor主要用来延迟之后执行任务或者定时执行任务,继承自ThreadPoolExecutor。功能与Timer类似,但ScheduledThreadPoolExecutor要更加强大、灵活。Timer对应的是单个线程,而ScheduledThreadPoolExecutor可以指定多个线程
源代码如下:
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
ScheduledThreadPoolExecutor为了实现周期性任务对ThreadPoolExecutor做了如下修改:
- 使用DelayedWorkQueue作为任务队列
- 获取任务的方式不同,同样都是队列的take,但增加了时间的判断
- 执行周期任务后,增加了额外的处理(需要把任务重新添加进队列)
核心方法
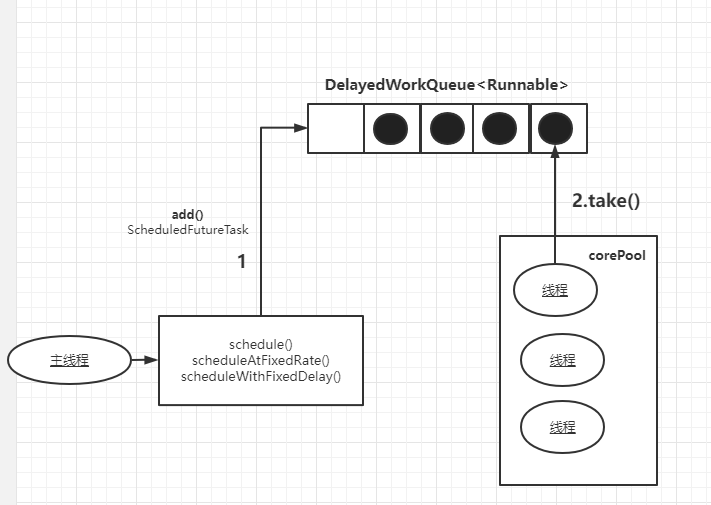
如上图所示,该线程池核心方法有三个,源代码如下:
/**
* 延迟执行一个异步任务
* command 异步任务
* delay 延迟时间
* unit 时间单位
*/
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<?> t = decorateTask(command,
new ScheduledFutureTask<Void>(command, null, triggerTime(delay, unit)));
delayedExecute(t);
return t;
}
/**
* 延迟执行一个有返回值的异步任务
* callable 有返回值的异步任务
* delay 延迟时间
* unit 时间单位
*/
public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit) {
if (callable == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<V> t = decorateTask(callable,
new ScheduledFutureTask<V>(callable, triggerTime(delay, unit)));
delayedExecute(t);
return t;
}
/**
* 延迟执行一个有周期性的异步任务
* command 异步任务
* initialDelay 延迟时间
* period 周期时间(每隔多长时间执行,不会考虑任务自身的运行时间)
* unit 时间单位
*/
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command, null, triggerTime(initialDelay, unit),
unit.toNanos(period));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
/**
* 延迟执行一个有周期性的异步任务
* command 异步任务
* initialDelay 延迟时间
* delay 周期时间(每隔多长时间执行,会在任务自身执行完后才开始计时)
* unit 时间单位
*/
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command, null, triggerTime(initialDelay, unit),
unit.toNanos(-delay));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
可以看到4个方法都创建了ScheduledFutureTask这个任务类,而且都执行了delayedExecute()方法:
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);
else {
super.getQueue().add(task);
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&
remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
里面最关键的就是把ScheduledFutureTask任务添加到了任务队列中;
不同的take()操作
我们看看和正常的线程池相比,该线程池take()到底有什么不同DelayedWorkQueue.take():
除了从头部取任务以外,还增加了时间的判断
public long getDelay(TimeUnit unit) {
return unit.convert(time - now(), NANOSECONDS);
}
public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
RunnableScheduledFuture<?> first = queue[0];
if (first == null)
available.await();
else {
long delay = first.getDelay(NANOSECONDS);
// 任务的time-当前时间<=0 即代表到时间该执行了
if (delay <= 0)
// 所以将任务从队列中取出执行
return finishPoll(first);
first = null; // don't retain ref while waiting
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}
任务执行的不同
因为是周期性任务,所以在执行后还需要将任务重新设置好时间再放入队列,ScheduledFutureTask.run():
public void run() {
// 判断任务是否是周期性任务 0:否 !=0:是
boolean periodic = isPeriodic();
if (!canRunInCurrentRunState(periodic))
cancel(false);
else if (!periodic)
ScheduledFutureTask.super.run();
else if (ScheduledFutureTask.super.runAndReset()) {
//设置下一次执行时间
setNextRunTime();
// 重新将任务放入队列
reExecutePeriodic(outerTask);
}
}
private void setNextRunTime() {
long p = period;
if (p > 0)
time += p;
else
time = triggerTime(-p);
}
void reExecutePeriodic(RunnableScheduledFuture<?> task) {
if (canRunInCurrentRunState(true)) {
// 放入队列
super.getQueue().add(task);
if (!canRunInCurrentRunState(true) && remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
如何保证即将执行的任务在队列头部
在任务add()入队的时候,如果头部已经存在任务,则会执行sifUp()方法:
说白了就是再每次入队的时候都会进行一次任务的时间对比,将要入队的任务找到在队列中合适的位置再插入进去,也就是队列中的任务都是根据执行时间有着先后顺序的
private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
int parent = (k - 1) >>> 1;
RunnableScheduledFuture<?> e = queue[parent];
// 对比任务的time时间 将改任务插入到队列中合适的执行位置
if (key.compareTo(e) >= 0)
break;
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
}
public int compareTo(Delayed other) {
if (other == this) // compare zero if same object
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
}
4.线程池五种状态
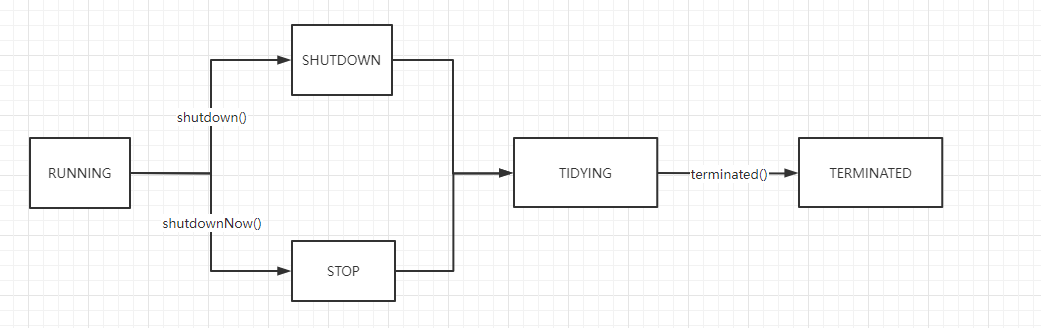
- RUNNING:处于该状态代表能接受新任务以及处理任务(初始状态)
- SHUTDOWN:处于该状态代表不接受新任务,但处理已添加的任务 (调用shutdown()时,由RUNNING->SHUTDOWN)
- STOP:处于该状态时,不接受新任务,不处理已添加任务,并会中断正在处理中的任务 (调用shutdownNow()时,由RUNNING或者SHUTDOWN→STOP)
- TIDYING:进入SHUTDOWN或者STOP状态后,所有任务都被处理或者清理干净后就会进入该状态,同时会执行terminated()方法(该方法是个钩子函数,自定义实现)
- TERMINATED:结束状态,执行完terminated后由TIDYING->TERMINATED
5.线程池内线程如何复用?
这得从往线程池提交一个任务说起了,execute()方法如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 1.小于核心线程数
if (workerCountOf(c) < corePoolSize) {
// 则添加一个核心工作线程 worker ,true代表核心工作线程
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2.大于核心线程数则将任务放入阻塞队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3.大于核心线程数且队列加入失败(队列满了),则添加一个非核心线程
else if (!addWorker(command, false))
// 非核心线程添加失败了(达到最大线程数),则执行拒绝策略
reject(command);
}
从上面可以看到提交一个任务的时候其实不是立马执行的,会有核心线程数、最大线程数、队列长度等判断,任务会被放入Worker工作线程中执行,线程池内部有一个Workers 的set集合用来管理所有的工作线程,所以说任务的最终执行时在Worker.run() 中的,复用的秘密也在这里面:
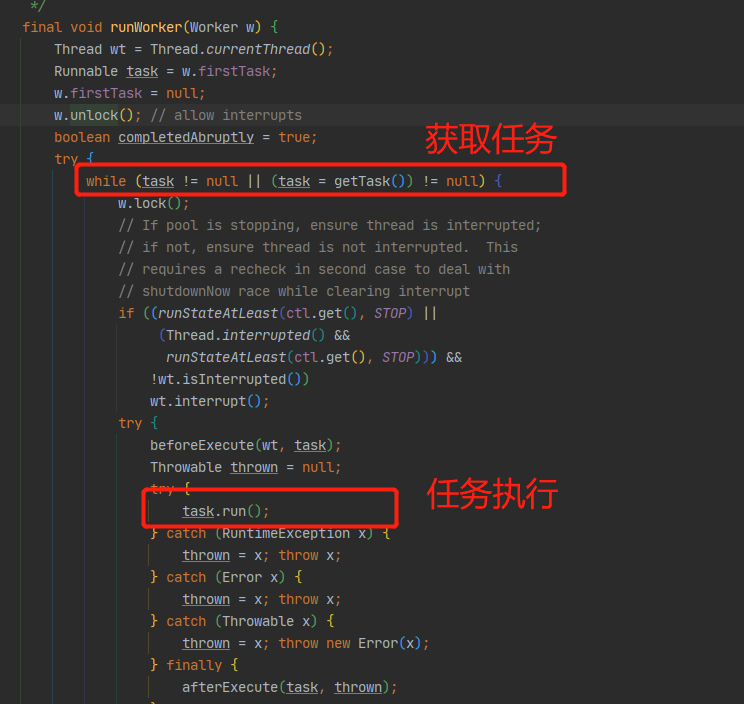
通过getTask()不断获取任务,然后执行,到了这你会发现核心线程和非核心线程好像一点区别都没有是吧?让我们看看getTask()方法:
private Runnable getTask() {
// 超时标记
boolean timedOut = false;
// 死循环
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// 判断是否超过核心线程数
// 超过了则会为true 下面将进行超时判断
// false则代表核心线程,下面将一直阻塞获取任务
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 通过timed来判断是阻塞获取 还是 一定时间内获取返回
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
// 超时了,上面的判断将会跳出
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
该方法可谓是核心线程和非核心线程最大的区别了:是否超时退出?
核心线程数:将会调用workQueue.take()方法,如果队列没有任务将会一直阻塞在这里,有任务则会取出执行,这就是核心线程复用的原理 非核心线程数:将会调用workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)方法,在达到keepAliveTime时间后将会返回null,代表超时了,最外层run方法的while循环也将会跳出,所以非核心线程会被回收
📌这里也需要注意一个点,因为默认核心线程难被回收,所以在使用的时候需要注意核心线程内所持有的对象内存回收问题
核心线程就一定不会退出吗?
不一定,在上述源代码中可以看到判断中有一个allowCoreThreadTimeOut变量,该变量默认是false,但是我们可以设置成true,那么核心线程也可以在keepAliveTime时间到后退出;
还有就是在代码中可以看到worker工作线程是没有明确的标识核心线程和非核心线程的,所以说核心线程只是保留的工作线程数量,在这个数量下都是核心线程,看哪个线程先被判断而已:
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
6.线程池内线程退出处理
线程池里面的线程退出后,做了些什么处理?
线程退出都会执行processWorkerExit()方法:
- 如果是异常退出需要把工作线程数减一
- 计算线程池已完成任务总数
- 在工作线程集合中移除当前线程
- 判断并维持线程池中最小工作线程数量
源代码如下:
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// 如果是异常退出,需要把工作线程数量减一
// 正常退出的话,在getTask方法里面已经减一了
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 计算线程池已完成任务总数
// 已完成任务总数+当前退出线程所完成的任务数
completedTaskCount += w.completedTasks;
// 在工作线程集合中移除
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
int c = ctl.get();
// 下面判断就是为了维持线程池中最小工作线程数量
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}
7.线程池使用注意事项及技巧
慎用Executors 创建线程池
谨慎使用FixedThreadPool、SingleThreadExecutor、CachedThreadPool三种池子:
- FixedThreadPool和SingleThreadExecutor:队列都采用了LinkedBlockingQueue,是无边界的任务队列,容易任务堆积导致OOM
- CachedThreadPool:最大线程池是无边界的,线程数量不可控,有风险
建议通过ThreadPoolExecutor指定参数创建
技巧
其实前面已经说了ThreadPoolExecutor的拓展功能,可以利用这个实现一些监控和告警规则,如:
- 自定义拒绝策略:在发生拒绝的时候,记录详细日志并告警
- 任务执行超时告警:根据afterExecute() 和 beforeExecute(),计算出任务执行时长,超过阈值则告警
- 队列容量告警:队列使用大小/队列设置的最大值,达到阈值后告警(比如达到85%告警)
- 自定义线程工厂:明确的区分线程池处理的是什么业务方便排查
- 自定义阻塞队列:比如可以实现队列使用内存的限制、队列长度动态调整