精选文章|零拷贝
作者:木匠 得物技术查看原文
本文说的零拷贝都是基于网络传输。
什么是零拷贝
零拷贝并不是不需要拷贝,而是减少不必要的拷贝次数。
传统IO流程
通常我们需要访问硬盘数据的时候,用户进程需要借助内核来访问硬盘的数据;用户通过调用系统方法,如read()、write()等方法通知内核,让内核做相应的事情。
read();
传统读取数据的流程:

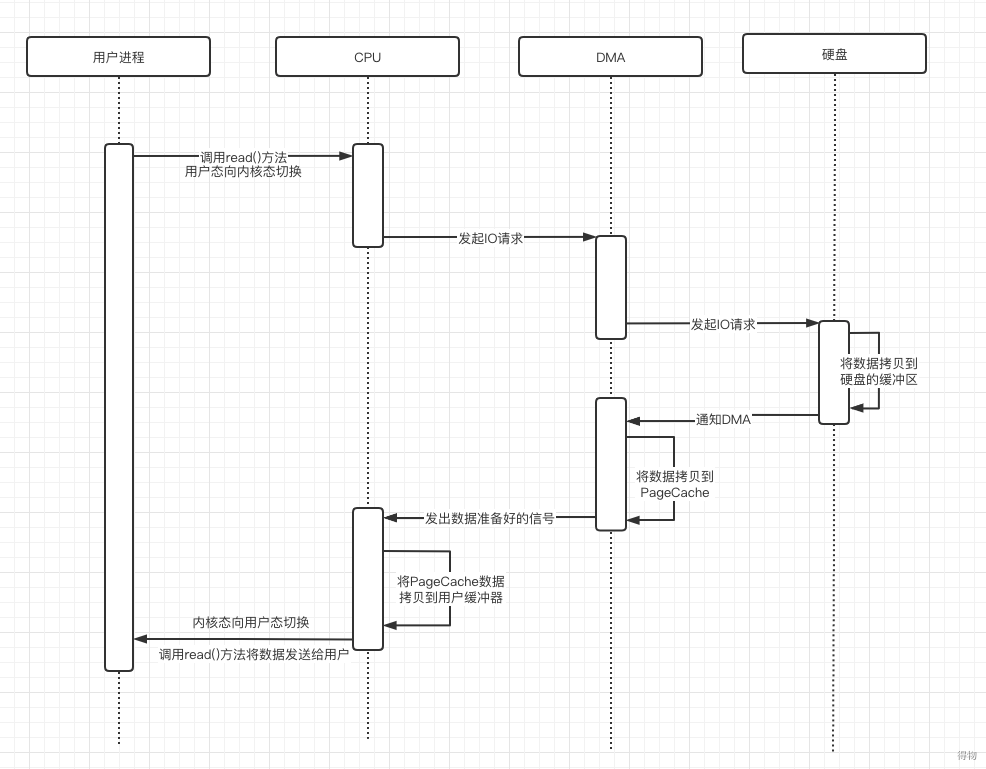
在没有DMA之前的拷贝流程如上图所示:
- 用户调用read系统方法。
- CPU收到read请求后,给磁盘发起一个对应的指令。
- 硬盘准备好数据,并将数据放到缓冲区中,给CPU发起IO中断指令。
- CPU收到中断指令后,暂停正在做得事情,将磁盘中的数据读取到内核缓冲区中。
- 紧接着,CPU将数据拷贝到用户缓冲区中
- 此时,用户便可访问数据。
以上流程中,涉及到数据的拷贝都需要CPU来完成,CPU是非常珍贵的资源,CPU在拷贝数据的时候,无法做其他的事情,如果传输的数据非常大,那么CPU一直在拷贝数据,无法执行其他工作,代价非常大。
DMA
本质上,DMA技术就是计算机主板上一块独立的芯片,当计算机需要在内存和 I/O 设备进行数据传输的时候,不再需要CPU来执行耗时的IO操作,而是通过DMA控制器来完成,流程如下。
- 上图可知,数据拷贝由DMA完成,CPU不需要在执行一些耗时的IO操作。
- 下图可以更形象的表达文件传输的过程:
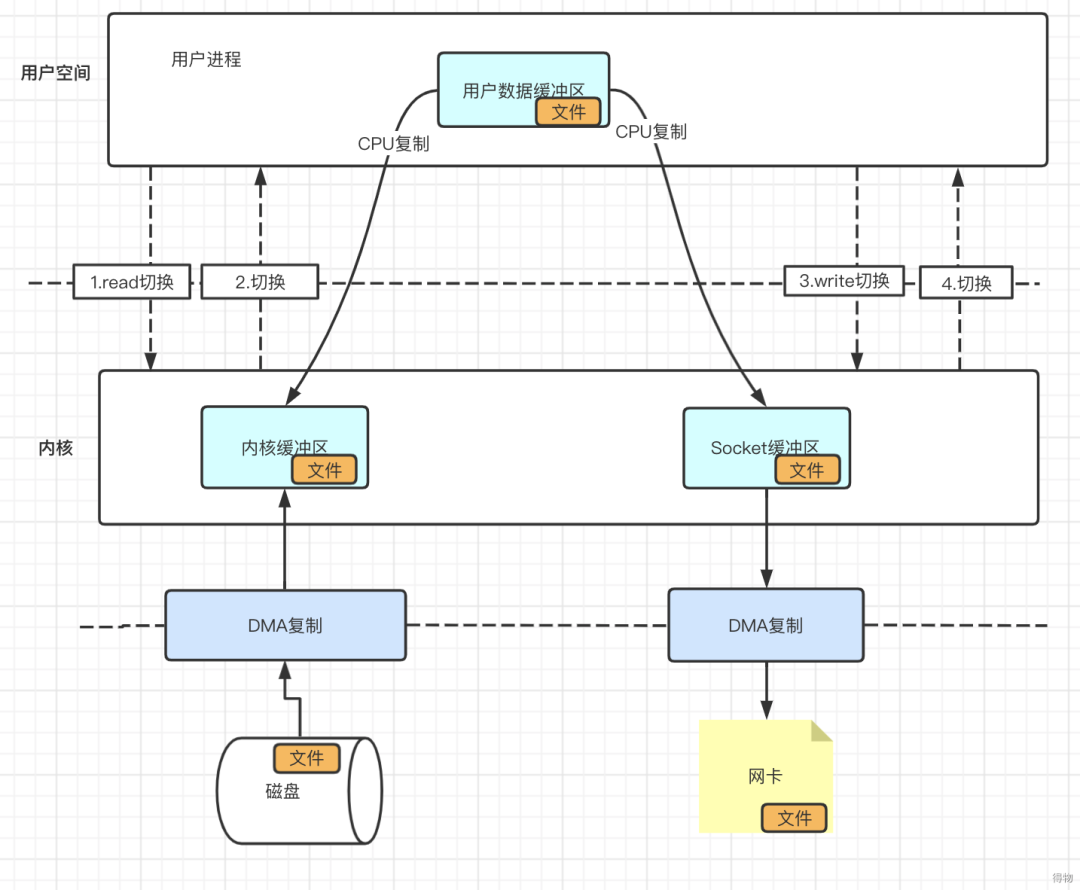
步骤说明如下:
- 用户进程调用系统函数read()。
- 内核接收到对应指令之后去磁盘将文件读取到内核缓冲区中,数据准备好之后发起一个IO中断。
- CPU收到IO中断信号之后停止手中的工作,将内核缓冲区中的数据拷贝到用户进程中。
- 用户进程收到数据之后调用系统函数write(),由CPU将数据拷贝到socket缓冲区中。
- 由DMA控制器将socket缓冲区中的数据拷贝到网卡中,进行数据传输。
以上传统的IO数据拷贝在性能上有很大的提升空间。
由上图看出,在文件传输的案例中,我们将数据拷贝到用户数据缓冲区,用户进程没有经过任何数据处理,将文件直接发送出去。因此,这一个步骤是多余的,可以省略。
实现零拷贝
零拷贝的实现主要是针对上下文切换和拷贝的次数进行优化,通过减少上下文切换和减少数据拷贝的次数来达到优化的目的。
实现方式一:mmap(..) + write(..)
什么是mmap
mmap全称Memory Mapped Files,是一种内存文件映射的方法,将一个文件或者其他对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中的一段虚拟地址的一一映射关系,映射关系生成之后,用户进程可以通过指针操作内存中的文件数据,系统会自动将操作后的数据写入到磁盘中,而不需要调用read(),write()等系统调用来操作数据。
实现过程
使用mmap()函数替换read()函数,mmap将内核缓冲区中的数据映射到用户空间,用户空间与内核之间就不需要进行数据的拷贝,他们可以进行数据共享。
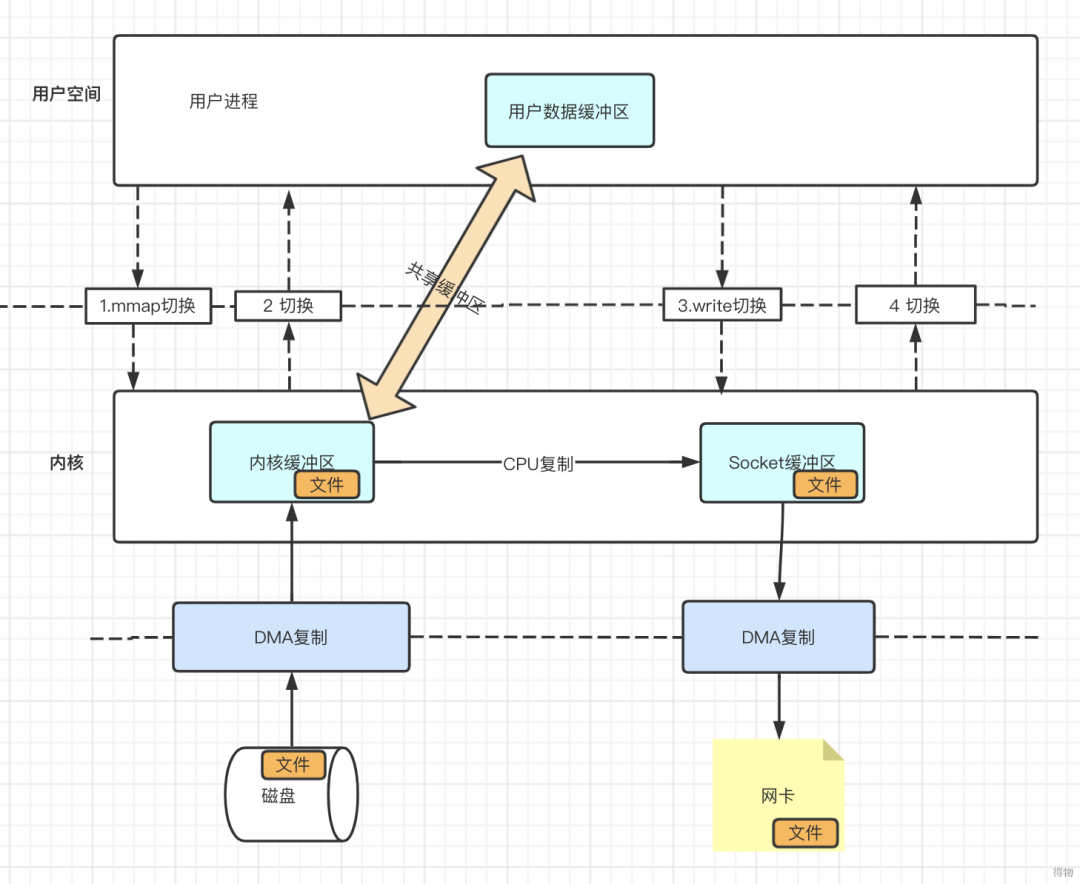
如图可以看出,数据不再拷贝到用户缓冲区。
- 用户进程调用系统函数mmap()后,DMA会将数据从磁盘拷贝到内核缓冲区中,用户进程与内核缓冲区共享这块内存数据;
- 用户进程调用write()函数,CPU将数据从内核缓冲区拷贝到socket缓冲区中。
- 最后,DMA将socket缓冲区中的数据拷贝到网卡中,进行数据发送。
mmap减少了一次数据的拷贝,性能有所提升,但还是存在4次用户态和内核态的切换,并不是最理想的零拷贝。
如何减少上下文切换?
用户进程没有权限直接操作磁盘的数据,内核拥有上帝的权限,所以用户进程可以通过调用系统函数(如read,wirte)将任务交给内核来完成。
一次系统调用会发生两次上下文切换,先从用户态切换到内核态执行任务,任务执行完成后,从内核态切换到用户态,用户进程继续执行逻辑。
上下文的切回需要耗费时间,每次上下文切换耗费几纳秒到几微妙,看起来时间很短,但在并发下会成倍放大。
因此,我们需要减少上下文切换的次数,要减少上下文切换的次数,就需要减少系统函数调用的次数。
实现方式二:sendfile 函数
Linux 2.1版本后提供了一个专门发送文件的系统调用函数sendfile(),函数如下:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
参数说明:
out_fd :目的地端的文件描述符
in_fd:源端的文件描述符
offset:源端的偏移量
count:复制的长度
返回实际复制数据的长度
sendfile函数用于代替read和write两个函数,这样就可以减少一次系统调用,减少两次上下文切换的开销。
$ ethtool -k eth0 | grep scatter-gatherscatter-gather: on
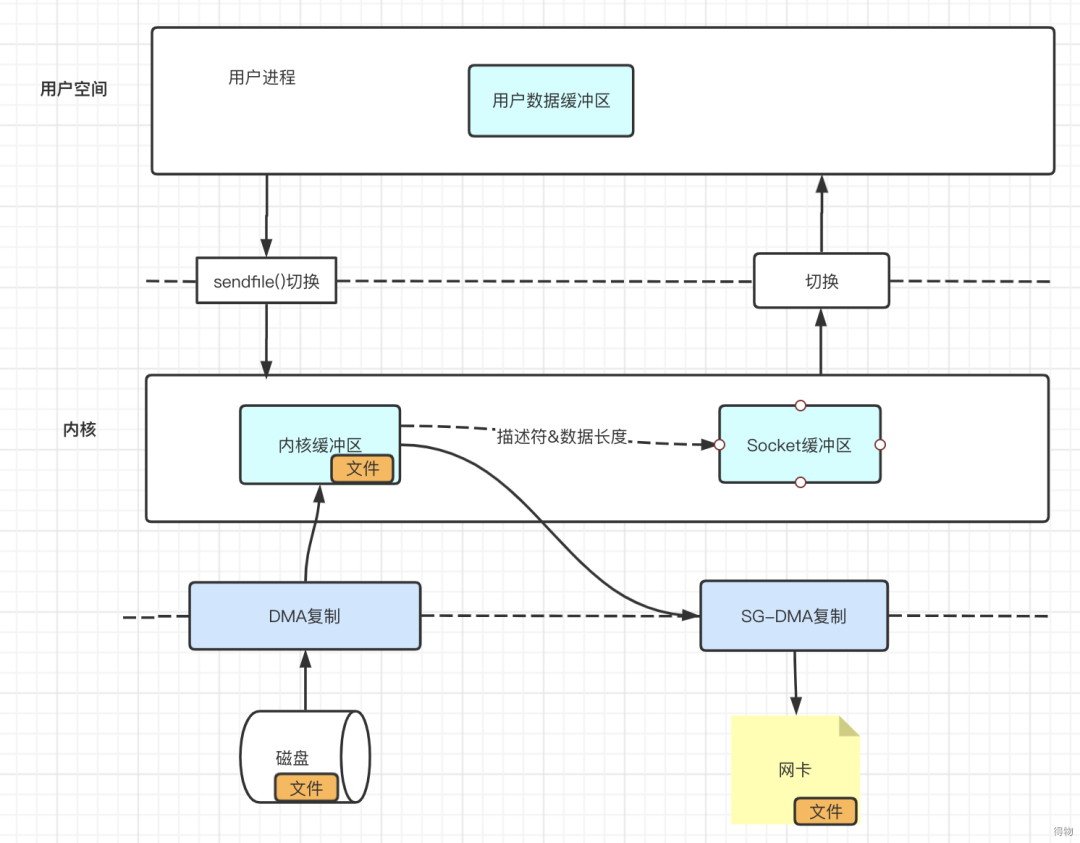
- DMA将磁盘中的数据拷贝到内核缓冲区
- 然后将内核缓冲区中的文件描述符和数据长度传送到socket中(不需要将数据拷贝到socket中)
- 网卡的SG-DMA控制器将内核缓冲区中的数据拷贝到网卡中,完成数据传输
以上过程只涉及到一次系统函数调用,2次上下文切换,2次DMA数据拷贝,不需要CPU拷贝数据,实现了真正的零拷贝。
mmap和sendfile对比
- 都是通过调用操作系统提供的API函数来实现。
- mmap为文件内存映射,用户进程对映射内存中的数据支持读和写操作,最终结果会反应在磁盘上。 sendfile将数据读取到内核缓冲区之后,网卡通过SG-DMA控制器将数据复制过来。
- mmap实现零拷贝涉及两次系统函数调用,产生4次上下文切换,三次数据拷贝,不属于真正意义上的零拷贝。 sendfile只有一次系统函数调用,产生2次上下文切换,2次必要的数据拷贝,实现了真正意义上的零拷贝。
- mmap优化更多的是在写请求上,sendfile更多是优化读请求。
内核缓冲区(PageCache)
PageCache为磁盘的高速缓冲区,由于在磁盘中找数据是非常耗时的操作,所以将磁盘中的部分数据缓存到PageCache中,将读写磁盘的操作转换到内存中,提高读写的效率。
PageCache内存空间相比于磁盘来说小很多,所以我们不可能把所有的数据放到磁盘中,那么我们需要将什么数据读取到内存中,读取多大?
PageCache使用了预读功能,假如我们需要读取32kb的数据,但是加载到内存中的数据不只是32kb,它会以页为单位(每页64kb)来读取数据,所以不仅会读取0-32kb的数据,还会读取32-64kb的数据,这样32-64kb部分的数据读取的代价非常小,如果在内存淘汰前被进程使用到,收益非常大。
所以PageCache有两个主要的好处:
- 缓存最近被访问的数据
- 预读功能
说白了PageCache的诞生就是为了提高磁盘的读写性能。
总结
- 零拷贝并不是不需要拷贝,而是减少不必要的拷贝,更要避免使用CPU进行数据拷贝。
- DMA拷贝技术很好的代替CPU拷贝。
- sendfile()函数实现了真正意义上的零拷贝,只需要2次DMA拷贝,1次系统函数调用,2次上下文切换。