HashTable
目录
一、基础常量以及结构
// 数组容器
private transient Entry<?,?>[] table;
// 容器容量
private transient int count;
// 扩容阈值
private int threshold;
// 扩容因子
private float loadFactor;
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
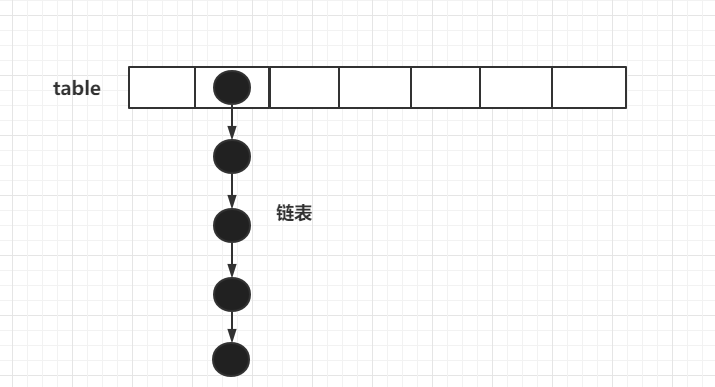
和HashMap不同,HashTable只有数组+链表,结构如下:
二、构造方法
public Hashtable() {
this(11, 0.75f);
}
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
可以看到初始化的时候就已经确定了容量大小和扩容大小,默认大小是11,默认扩容因子是0.75
三、put操作
- 根据hash获取数组下标
- 节点已经存在则遍历链表,如有相同的值则替换value ,否则 添加新节点
这个跟HashMap差不多的思路,就是没了树结构的操作,有两个特点就是不允许value为null,而且方法用synchronized 所修饰
源代码如下:
public synchronized V put(K key, V value) {
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
int hash = key.hashCode();
// 获取hash获取数组下标 (数组长度取余)
int index = (hash & 0x7FFFFFFF) % tab.length;
Entry<K,V> entry = (Entry<K,V>)tab[index];
// 节点不为空则遍历链表 已存在则替换value值
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
// 不存在则添加
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
// 添加前先判断是否需要扩容
if (count >= threshold) {
// 扩容
rehash();
// 获取扩容后数组
tab = table;
hash = key.hashCode();
// 扩容后重新计算需要添加节点的数组下标
index = (hash & 0x7FFFFFFF) % tab.length;
}
// 创建节点
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
四、rehash()扩容操作
HashTable扩容很简单就是正常的数组扩容:
- 新建一个数组,容量为之前的2倍+1
- 重新计算扩容阈值
- 遍历老的数组,重新计算每个节点的数组下标并放入新的数组
源代码如下:
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// 翻倍且+1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
// 重新计算扩容阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
// 遍历转移数据
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
// 重新计算每个节点数组下标
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
五、get操作
根据hash取下标,遍历对比取值,主要是被synchronized修饰
源代码如下:
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
六、contains 操作
containsValue
遍历数组内所有节点对比value值,被synchronized修饰
源代码如下:
public boolean containsValue(Object value) {
return contains(value);
}
public synchronized boolean contains(Object value) {
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<?,?> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
containsKey
遍历数组内所有节点对比key值,被synchronized修饰
源代码如下:
public synchronized boolean containsKey(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
总结
相比于HashMap,HashTable最大的区别就是线程安全,操作方法都被synchronized关键字所修饰,而且舍弃了树结构的优化,在容量方面也不在是2的n次方了