Java编译期注解处理器
作者:阿里开发者 查看原文
本文围绕编译器注解都是如何运行的呢? 又是怎么自动生成代码的呢?做出了详细介绍。
概述
我们接触的注解主要分为以下两类:
- 运行时注解: 通过反射在运行时动态处理注解的逻辑
- 编译时注解: 通过注解处理器在编译期动态处理相关逻辑
平时我们接触的框架大部分都是运行时注解,比如:@Autowire @Resoure @Bean 等等。
那么我们平时有接触过哪些编译期注解呢,@Lombok @AutoService 等等
像这些编译时注解的作用都是自动生成代码,一是为了提高编码的效率,二是避免在运行期大量使用反射,通过在编译期利用反射生成辅助类和方法以供运行时使用。
那这些编译器注解都是如何运行的呢? 又是怎么自动生成代码的呢?
我们今天来详细介绍一下,不过在介绍之前,可以先简单了解一下Java注解的基本概念
注解处理器
注解处理流程
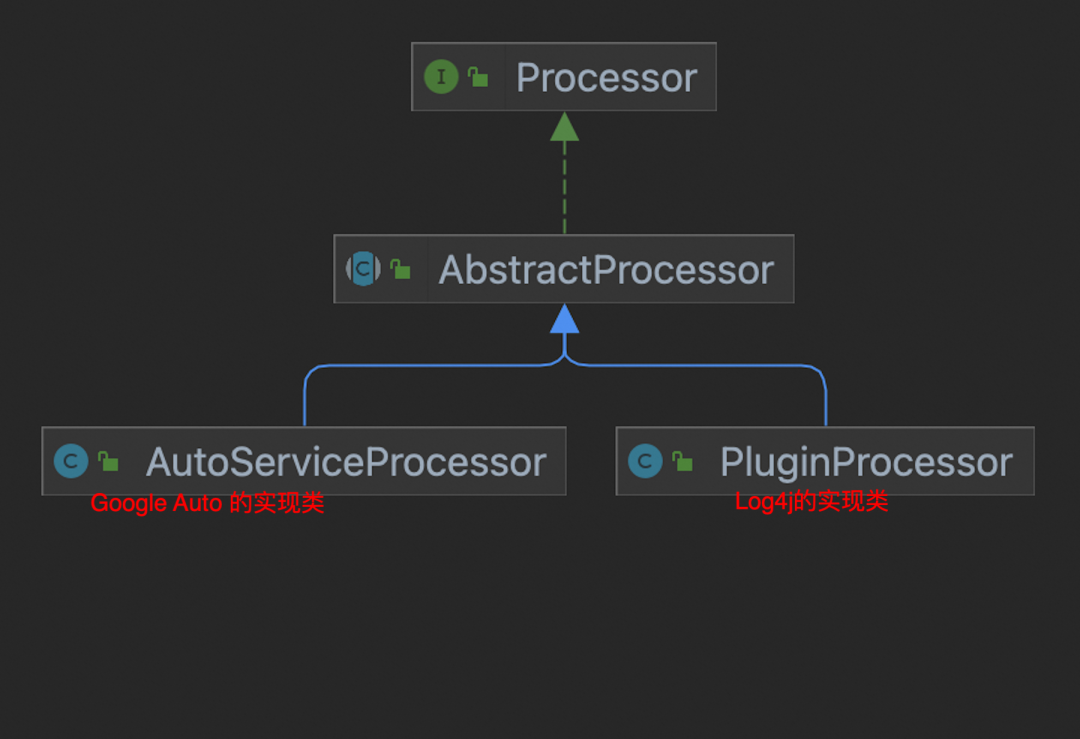
注解编译期处理流程最关键的一个类就是Processor ,它是注解处理器的接口类,我们所有需要对编译期处理注解的逻辑都需要实现这个Processor接口,当然,AbstractProcessor 抽象类帮我们写好了大部分都流程,所以我们只需要实现这个抽象类就可以很方便的定义一个注解处理器;
注解处理流程由多轮完成。每一轮都从编译器在源文件中搜索注解并选择适合这些注解的 注解处理器**(AbstractProcessor)** 开始。每个注解处理器依次在相应的源上被调用。
如果在此过程中生成了任何文件,则将以生成的文件作为输入开始另一轮。这个过程一直持续到处理阶段没有新文件生成为止。
注解处理器的处理步骤:
- 在java编译器中构建;
- 编译器开始执行未执行过的注解处理器;
- 循环处理注解元素(Element),找到被该注解所修饰的类,方法,或者属性;
- 生成对应的类,并写入文件;
- 判断是否所有的注解处理器都已执行完毕,如果没有,继续下一个注解处理器的执行(回到步骤1)。
AbstractProcessor
这是注解处理器的核心抽象类,我们主要来看看里面的方法
getSupportedOptions()
默认的实现是 从注解SupportedOptions获取值,该值是一个字符数组,例如
@SupportedOptions({"name","age"})
public class SzzTestProcessor extends AbstractProcessor {
}
不过貌似该接口并没有什么用处。
有资料表示 该可选参数可以从processingEnv获取到参数。
String resultPath = processingEnv.getOptions().get(参数);
实际上这个获取的参数是编译期通过入参 -Akey=name 设置的,跟getSupportedOptions没有什么关系。
getSupportedAnnotationTypes
获取当前的注解处理类能够处理哪些注解类型,默认实现是从SupportedAnnotationTypes注解里面获取;
注解值是个字符串数组 String [] ;
匹配上的注解,会通过当前的注解处理类的 process方法传入。
例如下面使用 * 通配符支持所有的注解:
@SupportedAnnotationTypes("*")
@SupportedSourceVersion(SourceVersion.RELEASE_11)
public class PrintingProcessor extends AbstractProcessor {
}
又或者可以直接重写这个接口:
@Override
public ImmutableSet getSupportedAnnotationTypes() {
return ImmutableSet.of(AutoService.class.getName());
}
最终他们生效的地方就是用来做过滤,因为处理的时候会获取到所有的注解,然后根据这个配置来获取自己能够处理的注解。
getSupportedSourceVersion
获取该注解处理器最大能够支持多大的版本,默认是从注解 SupportedSourceVersion中读取,或者自己重写方法,如果都没有的话 默认值是 RELEASE_6
@SupportedSourceVersion(SourceVersion.RELEASE_11)
public class PrintingProcessor extends AbstractProcessor {
}
或者重写(推荐 , 获取最新的版本)
@Override
public SourceVersion getSupportedSourceVersion() {
//设置为能够支持最新版本
return SourceVersion.latestSupported();
}
init初始化
init是初始化方法,这个方法传入了ProcessingEnvironment 对象。一般我们不需要去重写它,直接使用抽象类就行了。
当然你也可以根据自己的需求来重写
@Override
public synchronized void init(ProcessingEnvironment pe) {
super.init(pe);
System.out.println("SzzTestProcessor.init.....");
// 可以获取到编译器参数(下面两个是一样的)
System.out.println(processingEnv.getOptions());
System.out.println(pe.getOptions());
}
可以获取到很多信息,例如获取编译器自定义参数, 自定义参数的设置请看下面的 如何给编译期设置入参 部分
一些参数说明

process 处理方法
process方法提供了两个参数,第一个是我们请求处理注解类型的集合(也就是我们通过重写getSupportedAnnotationTypes方法所指定的注解类型),第二个是有关当前和上一次循环的信息的环境。
返回值表示这些注解是否由此 Processor 声明 如果返回 true,则这些注解不会被后续 Processor 处理; 如果返回 false,则这些注解可以被后续的 Processor 处理。
@Override
public boolean process(Setextends TypeElement> annotations, RoundEnvironment roundEnv) {
System.out.println("SzzTestProcessor.process.....;");
return false;
}
我们可以通过RoundEnvironment接口获取注解元素,注意annotations只是注解类型,并不知道哪些实例被注解标记了,RoundEnvironment是可以知道哪些被注解标记了的。
关于这部分的使用介绍,请看下面的自定义注解处理器范例。
如何注册注解处理器
上面介绍了注解处理器的一些核心方法,那么我们如何注册注解处理器呢?
并不是说我们实现了AbstractProcessor类就会生效,由于注解处理器(AbstractProcessor) 是在编译期执行的,而且它是作为一个Jar包的形式来生效,所以我们需要将注解处理器作为一个单独的Module来打包。 然后在需要使用到注解处理器的Module引用。
这个注解处理器 所在Module打包的时候需要注意:
因为AbstractProcessor本质上是通过ServiceLoader来加载的(SPI), 所以想要被成功注册上。则有两种方式:
一、配置SPI
1、在resource/META-INF.services文件夹下创建一个名为javax.annotation.processing.Processor的文件;里面的内容就是你的注解处理器的全限定类名;

2、设置编译期间禁止处理 Process,之所以这样做是因为,如果你不禁止Process,ServiceLoader就会去加载你刚刚设置的注解处理器,但是因为是在编译期,Class文件被没有被成功加载,所以会抛出下面的异常
服务配置文件不正确, 或构造处理程序对象javax.annotation.processing.Processor: Provider org.example.SzzTestProcessor not found时抛出异常错误
如果是用Maven编译的话,请加上如下配置 <compilerArgument>-proc:none</compilerArgument>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
<executions>
<execution>
<id>default-compile</id>
<configuration>
<compilerArgument>-proc:none</compilerArgument>
</configuration>
</execution>
<execution>
<id>compile-project</id>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
3、注解处理器打包成功,就可以提供给别的Module使用了
二、使用@AutoService 自动配置SPI的配置文件
@AutoService 是Google开源的一个小插件,它可以自动的帮我们生成META-INF/services 的文件,也就不需要你去手动的创建配置文件了。
当然,上面的 <compilerArgument>-proc:none</compilerArgument>参数也不需要了。
所以也就不会有编译期上述的问题xxx not found 问题了。因为编译的时候META-INF/services 还没有配置你的注解处理器,也就不会抛出加载异常了。
例如下面,使用@AutoService(Processor.class),他会自动帮我们生成对应的配置文件。
@AutoService(Processor.class)
public class SzzBuildProcessor extends AbstractProcessor {
}
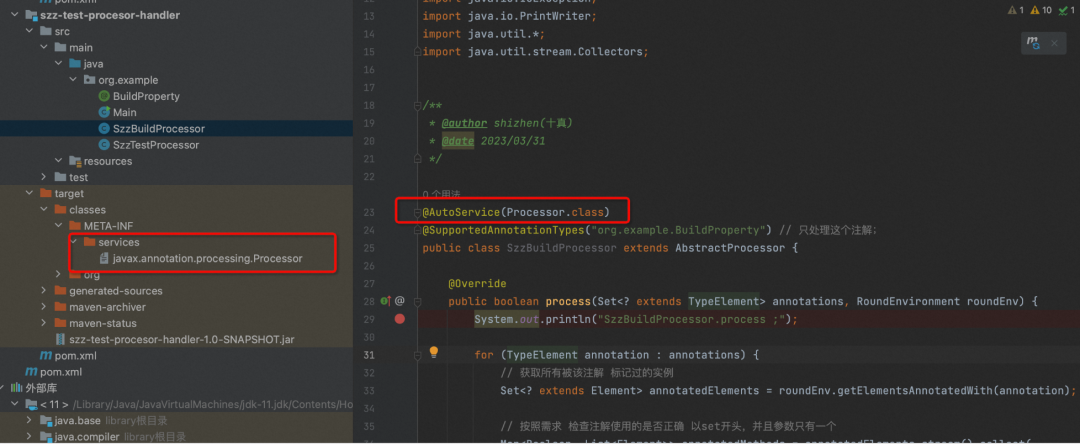
另外,实际上 @AutoService 自动生成配置文件也是通过AbstractProcessor来实现的。
如何调试编译期代码
在我们自己写了注解处理器之后,可能想要调试,那么编译期的调试跟运行期的调试不一样。
Maven相关配置(指定生效的Processor)
如果你使用的是Maven来编译,那么有一些参数可以设置。
比如指定注解处理器生效 、代码生成的源路径。默认是 target/generated-sources/annotations
除非特殊情况,一般不需要设置这些参数。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.5.1version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
<generatedSourcesDirectory>${project.build.directory} /generated-sources/generatedSourcesDirectory>
<annotationProcessors>
<annotationProcessor>
org.example.SzzTestProcessor
annotationProcessor>
annotationProcessors>
configuration>
plugin>
plugins>
<build>
注意事项
注解和注解处理器是单独的module:注解处理器只需要在编译的时候使用,注解的Module只需要引入注解处理器的Jar包就行了。因此我们需要将注解处理器分离为单独的module。
并且打包的时候请先打包注解处理器的Module.
自定义Processor类最终是通过打包成jar,在编译过程中调用的。
范例:自动生成Build构造器
1. 需求描述
假设我们的注释用户模块中有一些简单的 POJO 类,其中包含几个字段:
public class Company {
private String name;
private String email;
}
public class Personal {
private String name;
private String age;
}
我们想创建对应的构建器帮助类来更流畅地实例化POJO类
Company company = new CompanyBuilder()
.setName("ali").build();
Personal personal = new PersonalBuilder()
.setName("szz").build();
2. 需求分析
如果没有POJO都要手动的去创建对应的Build构建器,未免太繁杂了,我们可以通过注解的形式,去自动的帮我们的POJO类生成对应的Build构建器,但是当然不是每个都生成,按需生成;
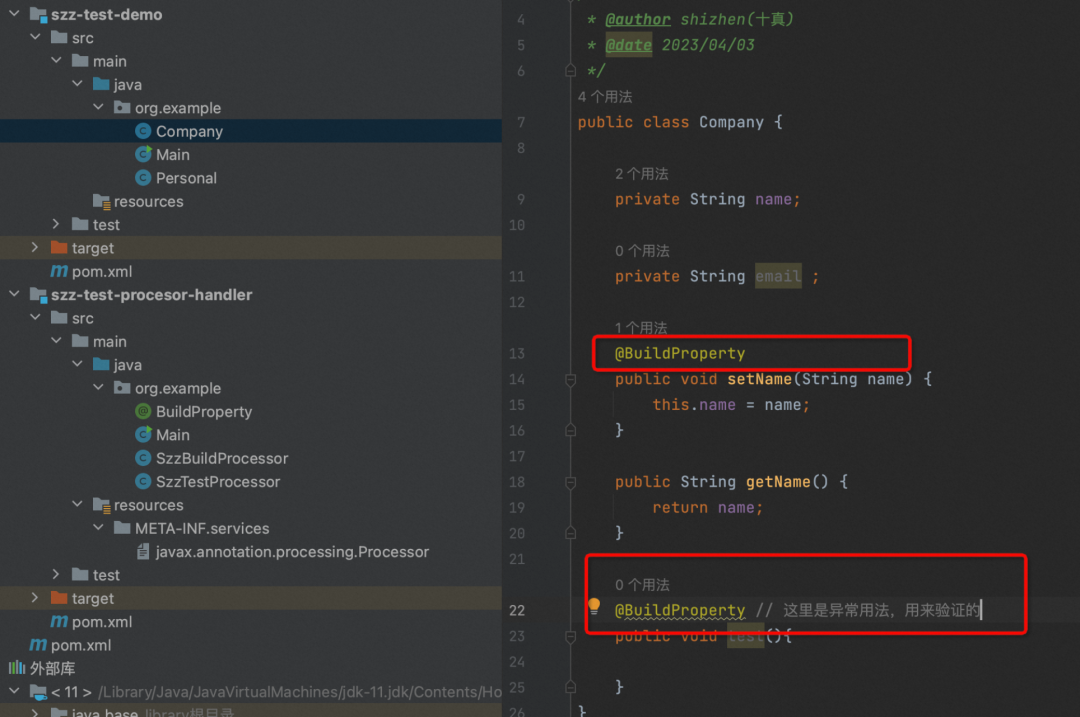
1、定义一个 @BuildProperty 注解,在需要生成对应的setXX方法的方法上标记注解
2、自定义 注解处理器扫描@BuildProperty注解,按照需求自动生成Build构建器。例如CompanyBuilder
public class CompanyBuilder {
private Company object = new Company();
public Company build() {
return object;
}
public CompanyBuilder setName(java.lang.String value) {
object.setName(value);
return this;
}
}
3、编码
创建一个注解处理器Module:szz-test-processor-handler
@BuildProperty
@Target(ElementType.METHOD) // 注解用在方法上
@Retention(RetentionPolicy.SOURCE) // 尽在Source处理期间可用,运行期不可用
public @interface BuildProperty {
}
注解处理器
@SupportedAnnotationTypes("org.example.BuildProperty") // 只处理这个注解;
public class SzzBuildProcessor extends AbstractProcessor {
@Override
public boolean process(Set annotations, RoundEnvironment roundEnv) {
System.out.println("SzzBuildProcessor.process ;");
for (TypeElement annotation : annotations) {
// 获取所有被该注解 标记过的实例
Set annotatedElements = roundEnv.getElementsAnnotatedWith(annotation);
// 按照需求 检查注解使用的是否正确 以set开头,并且参数只有一个
Map<Boolean, List> annotatedMethods = annotatedElements.stream().collect(
Collectors.partitioningBy(element ->
((ExecutableType) element.asType()).getParameterTypes().size() == 1
&& element.getSimpleName().toString().startsWith("set")));
List setters = annotatedMethods.get(true);
List otherMethods = annotatedMethods.get(false);
// 打印注解使用错误的case
otherMethods.forEach(element ->
processingEnv.getMessager().printMessage(Diagnostic.Kind.ERROR,
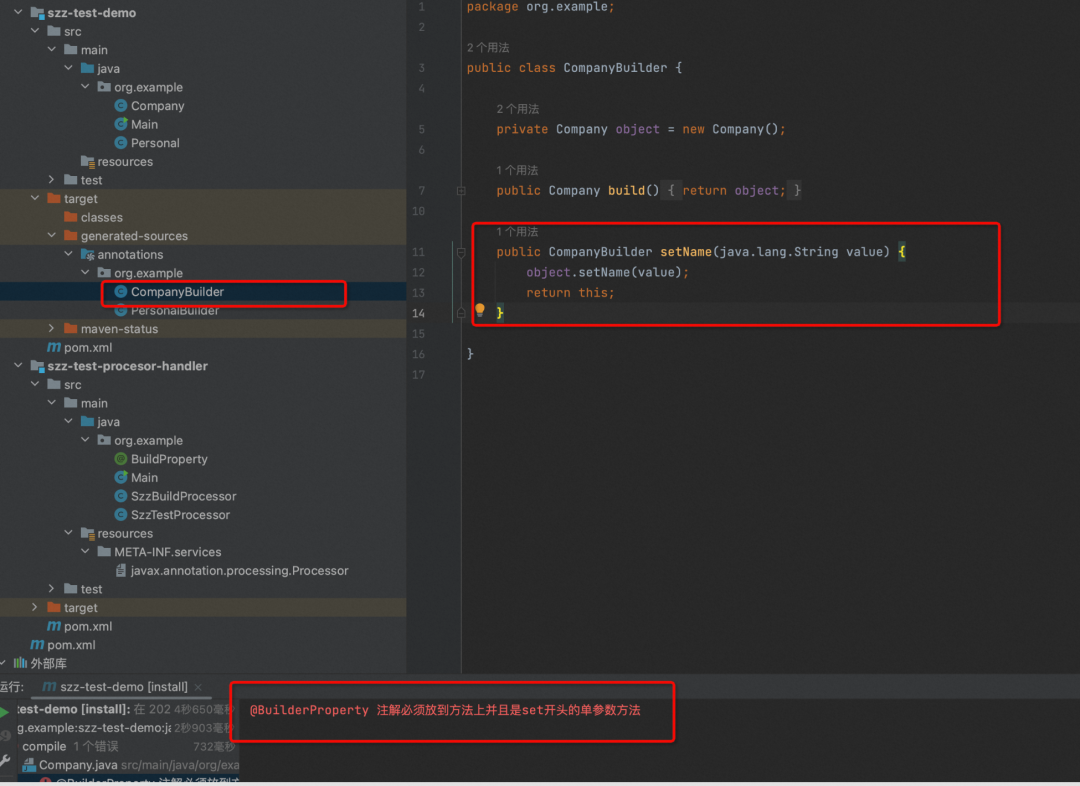
"@BuilderProperty 注解必须放到方法上并且是set开头的单参数方法", element));
if (setters.isEmpty()) {
continue;
}
Map> groupMap = new HashMap();
// 按照全限定类名分组。一个类创建一个Build
setters.forEach(setter ->{
// 全限定类名
String className = ((TypeElement) setter
.getEnclosingElement()).getQualifiedName().toString();
List elements = groupMap.get(className);
if(elements != null){
elements.add(setter);
}else {
List newElements = new ArrayList<>();
newElements.add(setter);
groupMap.put(className,newElements);
}
});
groupMap.forEach((groupSetterKey,groupSettervalue)->{
//获取 类名SimpleName 和 set方法的入参
Map setterMap = groupSettervalue.stream().collect(Collectors.toMap(
setter -> setter.getSimpleName().toString(),
setter -> ((ExecutableType) setter.asType())
.getParameterTypes().get(0).toString()
));
try {
// 组装XXXBuild类。并创建对应的类文件
writeBuilderFile(groupSetterKey,setterMap);
} catch (IOException e) {
throw new RuntimeException(e);
}
});
}
// 返回false 表示 当前处理器处理了之后 其他的处理器也可以接着处理,返回true表示,我处理完了之后其他处理器不再处理
return true;
}
private void writeBuilderFile(String className, Map setterMap) throws IOException {
String packageName = null;
int lastDot = className.lastIndexOf('.');
if (lastDot > 0) {
packageName = className.substring(0, lastDot);
}
String simpleClassName = className.substring(lastDot + 1);
String builderClassName = className + "Builder";
String builderSimpleClassName = builderClassName
.substring(lastDot + 1);
JavaFileObject builderFile = processingEnv.getFiler()
.createSourceFile(builderClassName);
try (PrintWriter out = new PrintWriter(builderFile.openWriter())) {
if (packageName != null) {
out.print("package ");
out.print(packageName);
out.println(";");
out.println();
}
out.print("public class ");
out.print(builderSimpleClassName);
out.println(" {");
out.println();
out.print(" private ");
out.print(simpleClassName);
out.print(" object = new ");
out.print(simpleClassName);
out.println("();");
out.println();
out.print(" public ");
out.print(simpleClassName);
out.println(" build() {");
out.println(" return object;");
out.println(" }");
out.println();
setterMap.entrySet().forEach(setter -> {
String methodName = setter.getKey();
String argumentType = setter.getValue();
out.print(" public ");
out.print(builderSimpleClassName);
out.print(" ");
out.print(methodName);
out.print("(");
out.print(argumentType);
out.println(" value) {");
out.print(" object.");
out.print(methodName);
out.println("(value);");
out.println(" return this;");
out.println(" }");
out.println();
});
out.println("}");
}
}
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
System.out.println("----------");
System.out.println(processingEnv.getOptions());
}
@Override
public SourceVersion getSupportedSourceVersion() {
return SourceVersion.latestSupported();
}
}
4、注册注解处理器
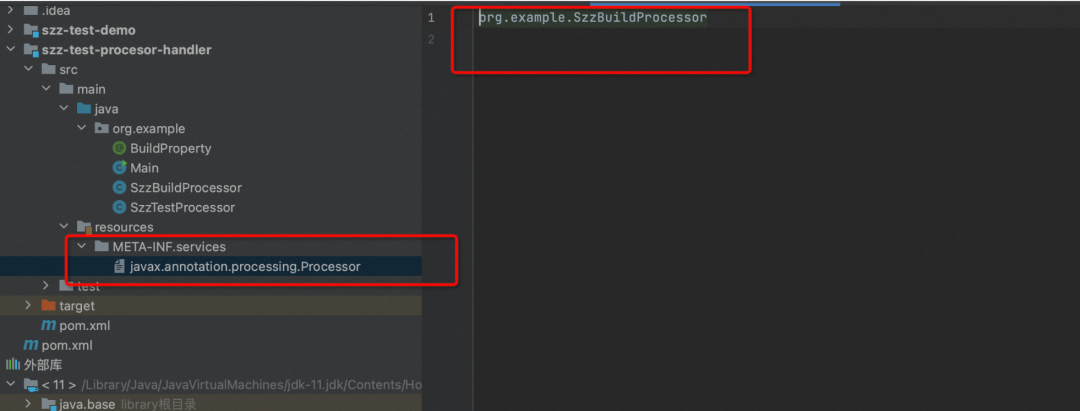
5、配置编译参数
因为这里选择的是手动配置了 META-INF.services; 所以我们需要配置一下编译期间忽略Processor;不然编译的时候就会被ServiceLoader加载,会抛出 class not found 的异常。 主要参数就是
<compilerArgument>-proc:none</compilerArgument>
如下所示
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.5.1version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
<executions>
<execution>
<id>default-compileid>
<configuration>
<compilerArgument>-proc:nonecompilerArgument>
configuration>
execution>
<execution>
<id>compile-projectid>
<phase>compilephase>
<goals>
<goal>compilegoal>
goals>
execution>
executions>
plugin>
plugins>
pluginManagement>
<build>
6、执行编译打包
mvn install一下, 其他Module就可以引用了。
7、Demo Module 依赖注解处理器
创建一个新的Module: szz-test-demo ; 让它依赖上面的 szz-test-processor-handler
并在Company的一些方法上使用注解。
8、Demo Module 进行编译,会自动生成BuildCompany类
Demo Module 编译之后,就会在target文件夹生成BuildXXX类。并且只有我们用注解BuildProperty标记了的方法才会生成对应的方法。
而且如果注解BuildProperty使用的方式不对,我们也会打印出来了异常。
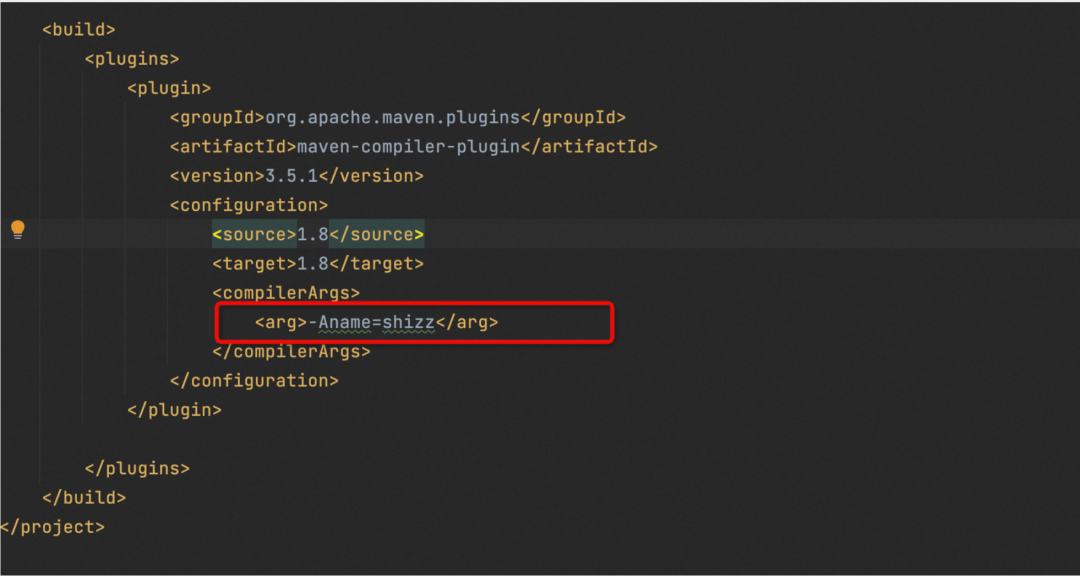
如何给编译期设置入参
在init初始化的接口中,我们可以获取到编译器的一些自定义参数;
String verify = processingEnv.getOptions().get("自定义key");
注意这个获取到的编译器参数只能获取的是以-A开头的参数,因为是过滤之后的
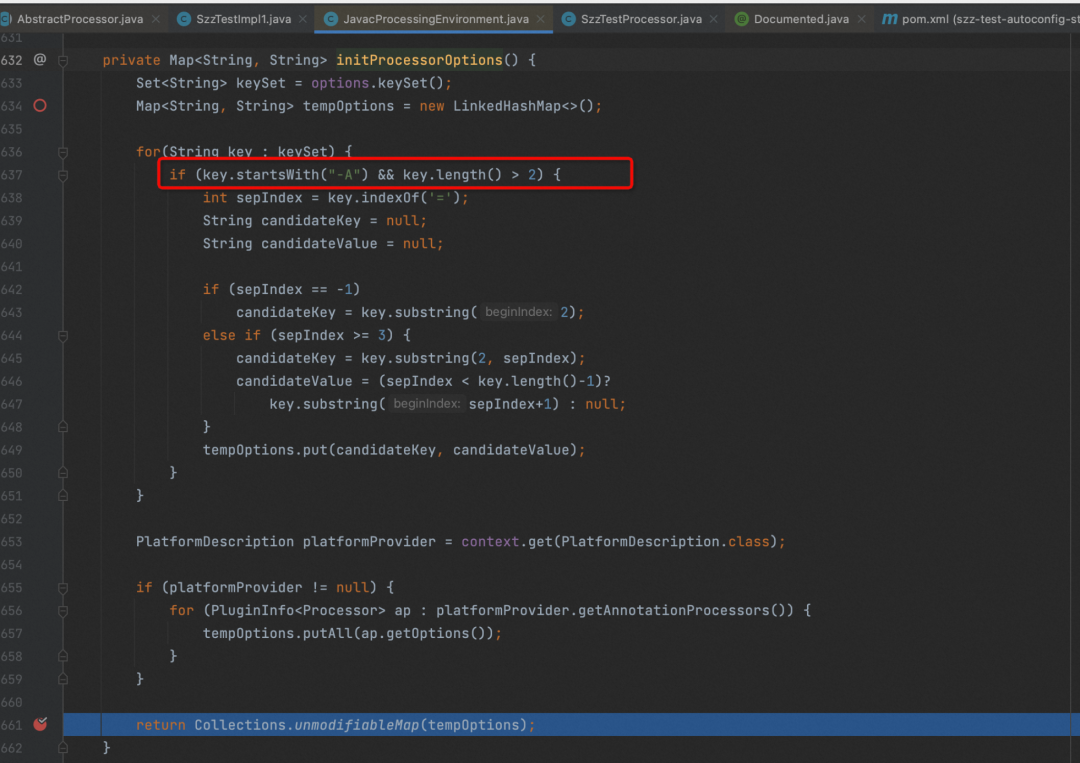
那么这个自定义参数从哪里设置的呢?
如果你是IDEA 编译
-Akey=value 或者 -Akey
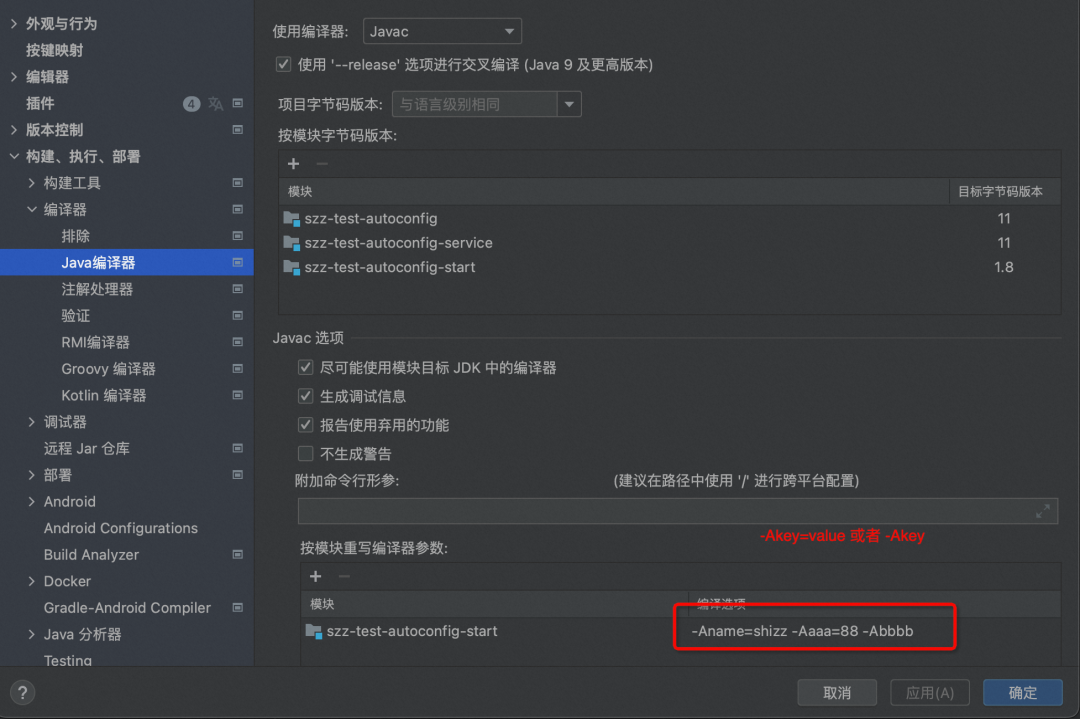
如果是用Maven编译