解码器的作用及实现
目录
- 拆包和沾包
- LineBasedFrameDecoder
- DelimiterBasedFrameDecoder
- FixedLengthFrameDecoder
- LengthFieldBasedFrameDecoder
- 总结
拆包和沾包
上一章已经介绍了使用Netty怎么简单的实现一个服务端和客户端,其中有没有什么问题呢?有,那就是典型的拆包和沾包问题,俗话说就是两端通信,一端发送一端接收,接收的那一端怎么知道是否已经完整的接收了数据?
假设服务端连续发送了两条消息:hello world! / hello client!
由于客户端不知道怎么才算一条消息,怎么才算两条消息,所以读取会有以下几种情况:
1.分两次读取消息,第一次是hello world!,第二次是hello client! 这是正常情况
2.一次就读取完成,hello world!hello client! 这种情况就叫沾包
3.分两次读取消息,第一次是hello ,第二次是world!hello client! 这第一次读取就是拆包,第二次就是沾包
总之就是读取到的信息不完整就是拆包,读取到的信息有额外多的信息就是沾包
演示
我们接着上一章的代码来演示,我们只需要让客户端发送消息的时候循环发送100次,服务端不变,看看服务端是不是接收到了100条消息
NettyClientTestHandler
结果如下:
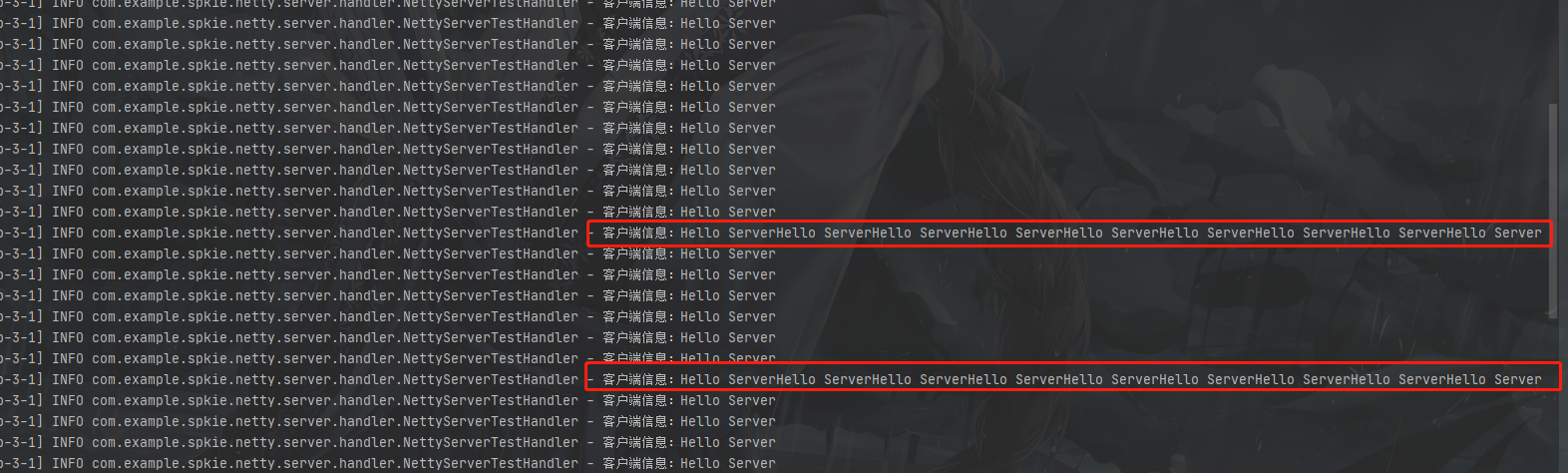
这明显就不对吧
解决方案
要怎么解决这种问题呢?
- 消息定长,每条消息都固定长度,不够则补空格
- 添加分隔符,等于是为每条消息都增加一个结束标识
- 将消息分为消息头和消息体,消息头固定长度,里面包含整条消息的长度或者消息体的长度
- 更复杂的协议约定
下面我们通过Netty中几种内置的解码器来解决这种问题:
- LineBasedFrameDecoder:行分隔符解码器(结尾根据 "\n" 作为结束标识)
- DelimiterBasedFrameDecoder:自定义分割器解码器,结尾根据什么作为结束标识可以自定义
- FixedLengthFrameDecoder:固定长度解码器,发送的消息需要定长
- LengthFieldBasedFrameDecoder:基于长度的自定义解码器,比较灵活
注意:所有编解码在Netty中都是数据处理管道当中的一个数据处理器而已
LineBasedFrameDecoder
这个是采用行分隔符来解决,所以我们需要改两个地方
1.发送消息的时候,消息结尾要加上行分隔符(接着上面的例子来)

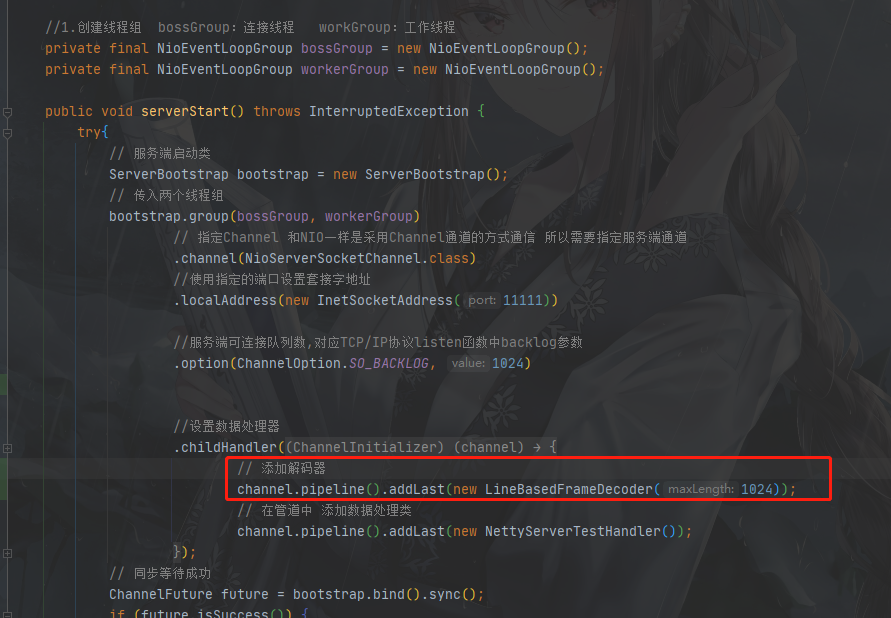
2.服务端接收消息,需要在管道内加入解码器
LineBasedFrameDecoder:传入的参数是消息最大长度,发送消息的大小必须小于设置值
结果如下:
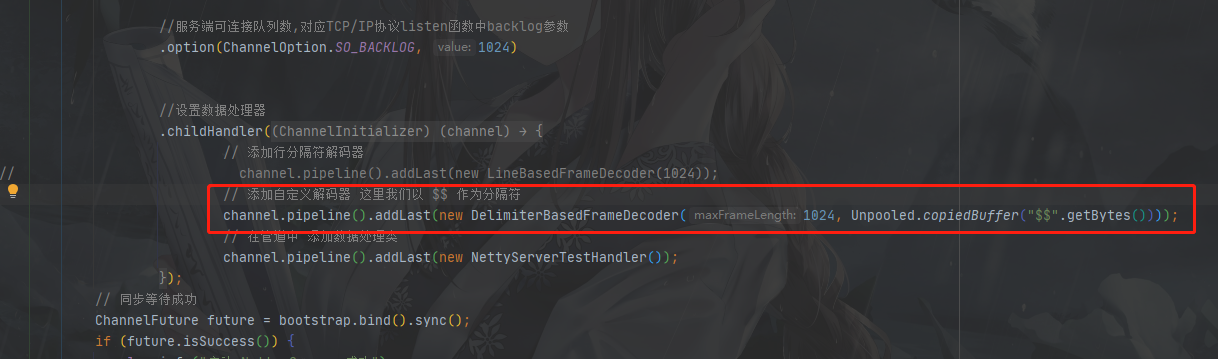
DelimiterBasedFrameDecoder
这个跟上面一样,只不过分隔符我们可以自定义
1.发送消息的时候,消息结尾要加上分隔符(这里我们定义分隔符是 "$$")
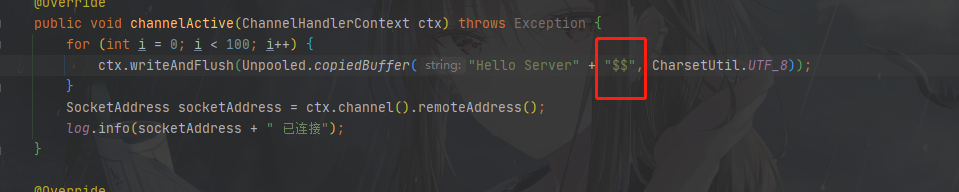
2.服务端接收消息,需要在管道内加入解码器
结果如下:
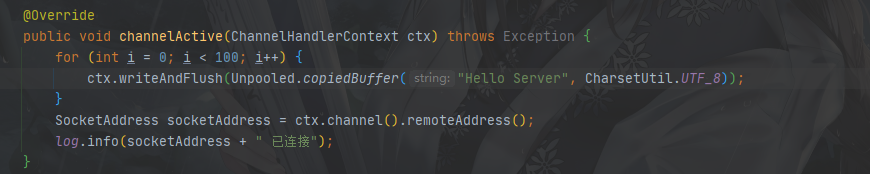
FixedLengthFrameDecoder
会按照设置的固定字节大小来切割消息
1.这里我们正常的发送消息就好了
2.服务端接收消息,需要在管道内加入解码器

结果如下:
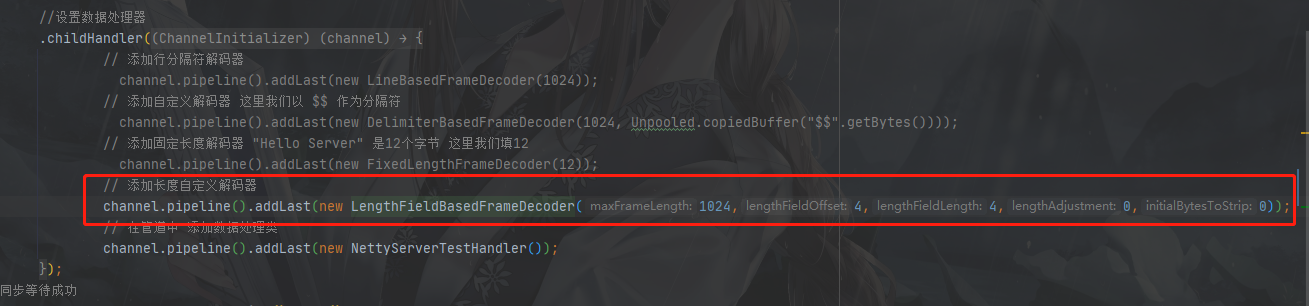
LengthFieldBasedFrameDecoder
这个是需要重点介绍一下的,上面三个解码器明显的看到不够灵活,太过于死板,我们看看这个怎么用
源代码构造如下
public LengthFieldBasedFrameDecoder(int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip) {
this(maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip, true);
}
参数含义:
- maxFrameLength:最大帧长度。也就是可以接收的数据的最大长度。如果超过,此次数据会被丢弃
- lengthFieldOffset:长度域偏移量。存储数据长度的一个偏移量
- lengthFieldLength:长度域字节数。存储数据长度的一个大小
- lengthAdjustment:数据长度修正。因为长度既可以代表data的长度,也可以是整个消息的长度
- initialBytesToStrip:跳过的字节数。可以选择舍弃一部分数据
这参数前三个可以比较好理解,后两个是干嘛的?没关系我们一步一步来,后两个先不用
假设我们要发送一个消息,结构为:消息头+数据长度+数据(Hello Server)
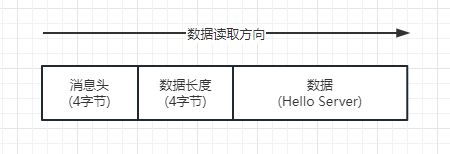
看看我们要怎么设置:
整体消息长度:20个字节、数据data长度:12字节
首先我们要找到长度域,所以要往右读取4个字节: lengthFieldOffset设置为4
然后需要读取数据的长度,所以需要再往右读4个字节: lengthFieldLength设置为4
之后会根据上面读取到的数据长度再往后读取数据:
假设这里数据长度是12,则会继续往后读取12个字节
至此数据就全读取完了(lengthAdjustment和initialBytesToStrip都设置成0的情况下)
下面我们演示一下:
NettyClientTestHandler
客户端发送消息,结构为:消息头+数据长度+数据
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
String data= "Hello Server";
ByteBuf buffer = Unpooled.buffer();
// 请求头 4字节
buffer.writeInt(666);
// 数据长度 4字节
buffer.writeInt(data.getBytes().length);
// 然后写入数据
buffer.writeBytes(Unpooled.copiedBuffer(data, CharsetUtil.UTF_8));
// 写入并发送 完整的数据为 666+12+Hello Server
ctx.writeAndFlush(buffer);
SocketAddress socketAddress = ctx.channel().remoteAddress();
log.info(socketAddress + " 已连接");
}
NettyServerTestHandler
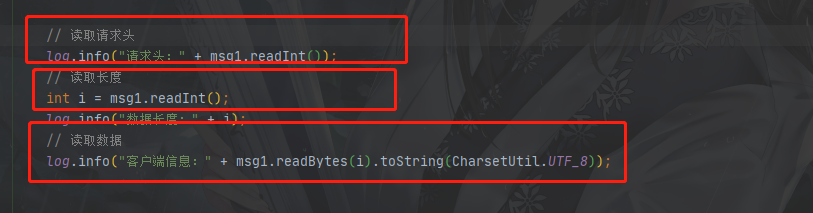
服务端按照结构解析消息
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
// 和NIO一样有缓冲区 ByteBuf就是对ByteBuffer做了一层封装
ByteBuf msg1 = (ByteBuf) msg;
// 读取请求头
log.info("请求头:" + msg1.readInt());
// 读取长度
int i = msg1.readInt();
log.info("数据长度:" + i);
// 读取数据
log.info("客户端信息:" + msg1.readBytes(i).toString(CharsetUtil.UTF_8));
}
服务端编码设置
结果如下:

initialBytesToStrip参数的作用
像上面这样沾包拆包的问题解决了,但是有一个点很麻烦,就是每次读取消息都需要一步一步的拆解消息,能不能把消息体前面无用的数据直接舍弃掉,只保留有用的数据部分呢?
可以!initialBytesToStrip参数就是可以在数据读取完后,可以选择跳过多少字节(你可以理解为舍弃,这样简单点),就像上面这个例子,我不需要请求头和数据长度的8个字节,我只需要后面的数据体,所以我可以将initialBytesToStrip设置成8
改动两个地方

服务端就不需要再拆解了,直接读取
lengthAdjustment参数的作用
上面我们知道了最后会根据长度域里面的数据来决定再往后读取多少个字节,这里我们设置的数据长度是12,所以刚刚好往后读取了12个字节,读取完成了,要是我设置的数据长度不是12呢?那往后读取多少个字节,这个是不是需要修正?
所以lengthAdjustment的作用就是来修正最终往后读取多少个字节
假设我设置的数据长度是20,代表了整个消息体的长度,但是我数据却只有12个字节,这往后读20个字节无疑是错的,所以我们需要修正,怎么修正? 减8呗,对吧
所以最终往后读取多少个字节=数据长度+lengthAdjustment
像上面为例,我们就需要设置成-8
总结
这章主要介绍了解码器的作用,沾包拆包的问题,但是还是存在一些问题:
- 每次发送消息都要写特定格式,是不是太麻烦了?(自定义编码器)
- 现在传输都是简单的字符串,实际都是实体类对象,这咋搞?(序列化和反序列化)
之后再介绍怎么自定义协议解决这些问题