服务发现优化之路
作者:金融级分布式架构 查看原文
SOFAStack (Scalable Open Financial Architecture Stack)是蚂蚁金服自主研发的金融级分布式架构,包含了构建金融级云原生架构所需的各个组件,是在金融场景里锤炼出来的最佳实践。
SOFARegistry 是蚂蚁金服开源的具有承载海量服务注册和订阅能力的、高可用的服务注册中心,最早源自于淘宝的初版 ConfigServer,在支付宝/蚂蚁金服的业务发展驱动下,近十年间已经演进至第五代。
本文为《剖析 | SOFARegistry 框架》第二篇,本篇作者尚彧,是 SOFARegistry 开源负责人。《剖析 | SOFARegistry 框架》系列由 SOFA 团队和源码爱好者们出品,项目代号:SOFA:RegistryLab/
https://github.com/sofastack/sofa-registry
概述
无论传统的 SOA 还是目前的微服务架构,都离不开分布式的特性,既然服务是分布的就必须解决服务寻址的问题。服务注册中心是这个过程最主要的组件,通过服务注册和服务发现特性收集服务供求关系,解耦服务消费方对服务提供方的服务定位问题。
服务注册中心的最主要能力是服务注册和服务发现两个过程。服务注册的过程最重要是对服务发布的信息进行存储,服务发现的过程是把服务发布端的所有变化(包括节点变化和服务信息变化)及时准确的通知到订阅方的过程。
本文详细描述服务注册中心 SOFARegistry 对于服务发现的实现和技术演进过程,主要涉及 SOFARegistry 的服务发现实现模式以及服务数据变化后及时推送到海量客户端感知的优化过程。
服务发现分类
分布式理论最重要的一个理论是 CAP 原理。关于注册中心的解决方案,根据存储数据一致性维度划分业界有很多实现,比如最有代表性的强一致性 CP 系统 ZooKeeper 和最终一致性 AP 系统 Eureka。SOFARegistry 在数据存储层面采用了类似 Eureka 的最终一致性的过程,但是存储内容上和 Eureka 在每个节点存储相同内容特性不同,采用每个节点上的内容按照一致性 Hash 数据分片来达到数据容量无限水平扩展能力。
服务端发现和客户端发现
抛开数据存储的一致性,我们从服务发现的实现维度考虑服务注册中心的分类,业界也按照服务地址选择发生主体和负载均衡策略实现主体分为客户端服务发现和服务端服务发现。
- 客户端服务发现:即由客户端负责决定可用的服务实例的"位置"以及与其相关的负载均衡策略,就是服务发现的地址列表在客户端缓存后由客户端自己根据负载均衡策略进行选址完成最终调用,地址列表定期进行刷新或服务端主动通知变更。最主要的缺点是需要有客户端实现,对于各种异构系统不同语言不同结构的实现必须要进行对应的客户端开发,不够灵活,成本较高。
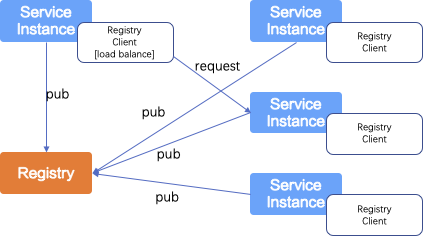
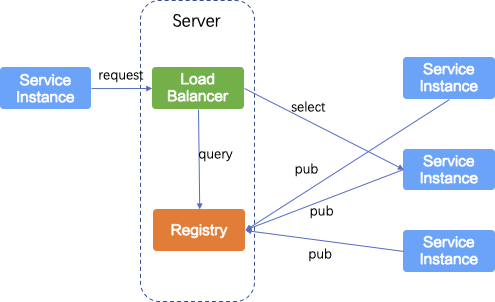
- 服务端服务发现:在服务端引入了专门的负载均衡层,将客户端与服务发现相关的逻辑搬离到了负载均衡层来做。客户端所有的请求只会通过负载均衡模块,其并不需要知会微服务实例在哪里,地址是多少。负载均衡模块会查询服务注册中心,并将客户端的请求路由到相关可用的微服务实例上。这样可以解决大量不同实现应用对客户端的依赖,只要对服务端的负载均衡模块发请求就可以了,由负载均衡层获取服务发现的地址列表并最终确定目标地址进行调用。
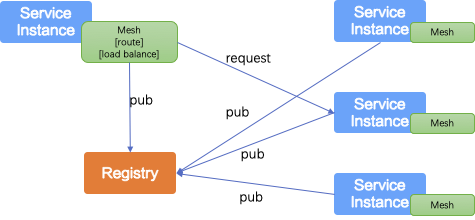
- SOFARegistry 服务发现模式:以客户端服务发现模式为主。这样的模式实现比较直接,因为在同一个公司内部实践面对的绝大多数应用基本上都是同一个语言实现的,客户端实现也只需要确定一套,每个客户端通过业务内嵌依赖方式部署,并且可以根据业务需求进行定制负载均衡策略进行选址调用。当然也会遇到特殊的异构系统,这个随着微服务架构 RPC 调用等通信能力下沉到 Mesh 执行也得到解决,可以在 Mesh 层进行特定的服务注册中心客户端嵌入,选择路由都在这里统一进行,对不同语言实现的系统进行无感知。
服务发现的推、拉模型
服务发现最重要的过程是获取服务发布方地址列表的过程,这个过程可以分为两种实现模式:客户端主动获取的拉模式和服务端主动变更通知的推送模式:
- 拉模式主要是在客户端按照订阅关系发起主动拉取过程。客户端在首次订阅可以进行一次相关服务 ID 的服务列表查询,并拉取到本地缓存,后续通过长轮询定期进行服务端服务 ID 的版本变更检测,如果有新版本变更则及时拉取更新本地缓存达到和服务端一致。这种模式在服务端可以不进行订阅关系的存储,只需要存储和更新服务发布数据。由客户端主动发起的数据获取过程,对于客户端实现较重,需要主动获取和定时轮训,服务端只需要关注服务注册信息的变更和健康情况及时更新内存。这个过程由于存在轮训周期,对于时效性要求不高的情况比较适用。
- 推模式主要是从服务端发起的主动变更推送。这个模式主要数据压力集中在服务端,对于服务注册数据的变更和提供方,节点每一次变更情况都需要及时准确的推送到客户端,更新客户端缓存。这个数据推送量较大,在数据发布频繁变更的过程,对于大量订阅方的大量数据推送频繁执行,数据压力巨大,但是数据变更信息及时,对于每次变更都准确反映到客户端。

- SOFARegistry 服务发现模式采用的是推拉结合方式。 客户端订阅信息发布到服务端时可以进行一次地址列表查询,获取到全量数据,并且把对应的服务 ID 版本信息存储在 Session 回话层,后续如果服务端发布数据变更,通过服务 ID 版本变更通知回话层 Session,Session 因为存储客户端订阅关系,了解哪些客户端需要这个服务信息,再根据版本号大小决定是否需要推送给这个版本较旧的订阅者,客户端也通过版本比较确定是否更新本次推送的结果覆盖内存。此外,为了避免某次变更通知获取失败,定期还会进行版本号差异比较,定期去拉取版本低的订阅者所需的数据进行推送保证数据最终一致。
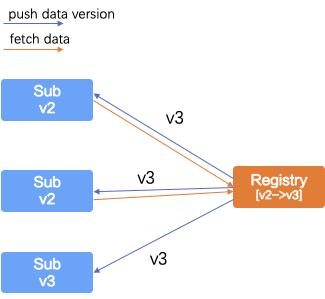
SOFARegistry 服务发现模式
数据分层
前面的文章介绍过 SOFARegistry 内部进行了数据分层,在服务注册中心的服务端因为每个存储节点对应的客户端的链接数据量有限,必须进行特殊的一层划分用于专门收敛无限扩充的客户端连接,然后在透传相应的请求到存储层,这一层是一个无数据状态的代理层,我们称之为 Session 层。
此外,Session 还承载了服务数据的订阅关系,因为 SOFARegistry 的服务发现需要较高的时效性,对外表现为主动推送变更到客户端,所以推送的主体实现也集中在 Session 层,内部的推拉结合主要是通过 Data 存储层的数据版本变更推送到所有 Session 节点,各个 Session 节点根据存储的订阅关系和首次订阅获取的数据版本信息进行比对,最终确定推送给那些服务消费方客户端。
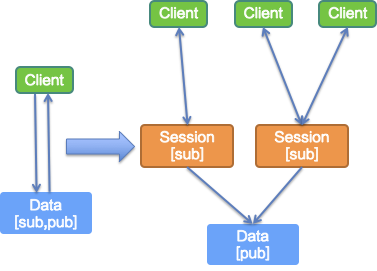
触发服务推送的场景
直观上服务推送既然是主动的,必然发生在主动获取服务时刻和服务提供方变更时刻:
- 主动获取:服务订阅信息注册到服务端时,需要查询所有的服务提供方地址,并且需要将查询结果推送到客户端。这个主动查询并且拉取的过程,推送端是一个固定的客户端订阅方,不涉及服务 ID 版本信息判定,直接获取列表进行推送即可,主要发生在订阅方应用刚启动时刻,这个时期可能没有服务发布方发布数据,会查询到空列表给客户端,这个过程基本上类似一个同步过程,体现为客户端一次查询结果的同步返回。
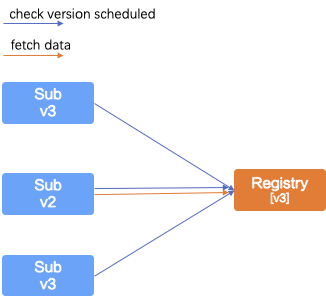
- 版本变更:为了确定服务发布数据的变更,我们对于一个服务不仅定义了服务 ID,还对一个服务 ID 定义了对应的版本信息。服务发布数据变更主动通知到 Session 时,Session 对服务 ID 版本变更比较,高版本覆盖低版本数据,然后进行推送。这次推送是比较大面积的推送,因为对于这个服务 ID 感兴趣的所有客户端订阅方都需要推送,并且需要按照不同订阅维度和不同类型的客户端进行数据组装,进行推送。这个过程数据量较大,并且需要所有订阅方都推送成功才能更新当前存储服务 ID 版本,需要版本更新确认,由于性能要求必须并发执行并且异步确定推送成功。
- 定期轮训:因为有了服务 ID 的版本号,Session 可以定期发起版本号比较,如果Session 存储的的服务 ID 版本号低于dataServer存储的 ,Session再次拉取新版本数据进行推送,这样避免了某次变更通知没有通知到所有订阅方的情况。
服务推送性能优化
服务订阅方的数量决定了数据推送一次的数量,对于一台 Session 机器来说目前我们存储 sub 数量达到60w+,如果服务发布方频繁变更,对于每次变更推送量是巨大的,故我们对整个推送的过程进行优化处理:
- 服务发布方频繁变更优化:在所有业务集群启动初期,每次对于一个相同的服务,会有很多服务提供方并发不停的新增,如果对于每次新增的提供方都进行一次推送显然不合理,我们对这个情况进行服务提供方的合并,即每个服务推送前进行一定延迟等待所有pub新增到一定时间进行一次推送。这个处理极大的减少推送的频率,提升推送效率。

- 即使对服务变更进行了合并延迟处理,但是推送任务产生也是巨大的,所以对于瞬间产生的这么大的任务量进行队列缓冲处理是必须的。目前进行所有推送任务会根据服务 ID、推送方 IP 和推送方信息组成唯一任务 ID 进行任务入队处理。队列当中如果是相同的服务变更产生推送任务,则进行任务覆盖,执行最后一次版本变更的任务。此外任务执行进行分批次处理,批次大小可以配置,每个批次处理完成再获取任务批次进行处理。
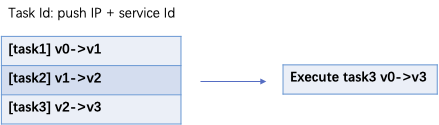
异常处理
对于这么大数据量的推送过程必然会因为网络等因素推送失败,对于失败的异常推送场景我们如何处理:
- 重试机制:很显然推送失败的客户端订阅依然还在,或者对应的链接还存在,这个失败的推送必须进行重试,重试机制定义十分重要。
- 目前对于上述首次启动主动获取数据进行推送的重试进行了有限次重试,并且每次重试之前进行网络监测和新版本变更检测,此外进行了时间延迟间隔,保证网络故障重试的成功几率。
- 这个延迟重试,最初我们采用简单的 sleep 方式,终止当前线程然后再发起推送请求。这个方式对于资源消耗巨大,如果出现大量的任务重试,会产生大量的线程停止占用内存,同时 sleep 方式对于恢复运行也不是很准确,完全取决于系统调度时间。后续我们对重试任务进行时间轮算法分片进行,对于所有重试任务进行了时间片定义,时间轮询执行对应时间片重试任务执行,效率极大提升,并且占用资源很小。
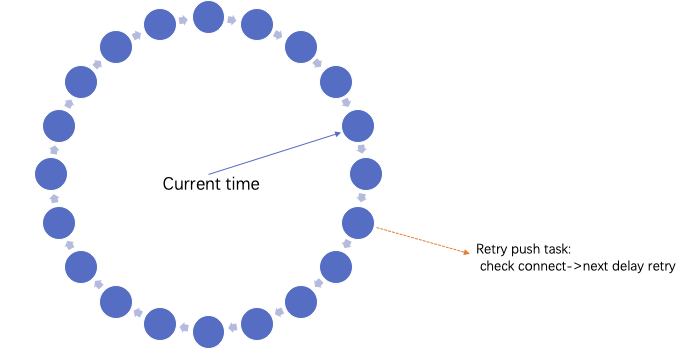
- 补偿措施:对于推送失败之前也说有定时任务进行轮训服务 ID 版本,服务 ID 的版本在所有推送方都接受到这个版本变更推送才进行更新,如果有一个订阅方推送失败,就不更新版本。后续持续检查版本再启动任务,对没有推送成功的订阅方反复执行推送,直到推送成功或者订阅方不存在,这个过程类似于无限重试的过程。
数据处理分阶段
注册中心数据的来源主要来自于两个方向,一个是大量应用客户端新连接上来并且发布和订阅数据并存储在注册中心的阶段,另外一个是之前这些发布的服务数据必须按照订阅方的需求推送出去的阶段。这两个阶段数据量都非常巨大,都在首次部署注册中心后发生,如果同时对服务器进行冲击网络和 CPU 都会成为瓶颈,故我们通过运维模式进行了两个阶段数据的分离处理:
- 关闭推送开关:我们在所有注册中心启动初期进行了推送开关关闭的处理,这样在服务注册中心新启动或者新发布初期,因为客户端有本地缓存,在推送关闭的情况下,注册中心的启动只从客户端新注册数据,没有推送新的内容给客户端,做到对现有运行系统最小影响。并且,由于推送关闭,数据只处理新增的内容这样对网络和 CPU 压力减少。
- 开推送:在关闭推送时刻记录没有推送过的订阅者,所有数据注册完成(主要和发布之前的数据数量比较),没有明显增长情况下,打开推送,对于所有订阅方进行数据推送更新内存。
总结
面对海量的数据进行服务注册和服务推送,SOFARegistry 采用了数据合并、任务合并处理,对于数据注册和数据推送两个大量数据过程进行了分开处理,并且在数据推送失败进行了重试机制优化,以及进行了定期版本号比对机制保证了数据一致性。