Session存储策略
作者:金融级分布式架构 查看原文
SOFAStack (Scalable Open Financial Architecture Stack)是蚂蚁金服自主研发的金融级分布式架构,包含了构建金融级云原生架构所需的各个组件,是在金融场景里锤炼出来的最佳实践。
SOFARegistry 是蚂蚁金服开源的具有承载海量服务注册和订阅能力的、高可用的服务注册中心,在支付宝/蚂蚁金服的业务发展驱动下,近十年间已经演进至第五代。
本文为《剖析 | SOFARegistry 框架》第五篇,本篇作者力鲲,来自蚂蚁金服。《剖析 | SOFARegistry 框架》系列由 SOFA 团队和源码爱好者们出品,项目代号:SOFA:RegistryLab:/
GitHub 地址:
https://github.com/sofastack/sofa-registry
回顾:服务注册
SOFARegistry 作为服务注册中心,面临的一个很重要的挑战就是如何解决海量的客户端连接问题,这也是本文要剖析的内容。不过作为一篇完整的文章,我们还是会先花一点时间介绍 SOFARegistry 的相关信息,以便读者了解其背景。
服务注册中心在服务调用的场景中,扮演一个“中介”的角色,服务发布者 (Publisher) 将服务发布到服务注册中心,服务调用方 (Subscriber) 通过访问服务注册中心就能够获取到服务信息,进而实现调用。
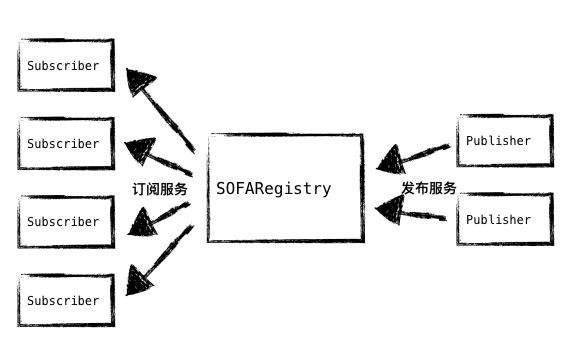
图1 - 服务的“中介”
流程:订阅/发布
在《海量数据下的注册中心 - SOFARegistry 架构介绍》一文中,我们提到了一个典型的 “RPC 调用的服务寻址” 应用场景,服务的提供方通过如下两个步骤完成服务发布:
- 注册,将自己以 Publisher 的角色注册到 SOFARegistry;
- 发布,将需要发布的数据 (通常是IP 地址、端口、调用方式等) 发布到 SOFARegistry;
与此相对应的,服务的调用方通过如下步骤实现服务调用:
- 注册,将自己以 Subscriber 的角色注册到 SOFARegistry;
- 订阅,收到 SOFARegistry 推送的服务数据;
从上面我们可以看到,整个流程中很重要的一个步骤就是注册,不管是 Publisher 还是 Subscriber 都只能在注册成功后才能实现发布订阅的需求。因此 SOFARegistry 要解决的一个问题就是如何维护与 Client 连接而产生的 Session,尤其是当 Client 数量众多的时候。
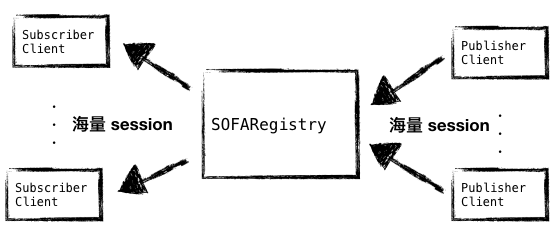
图2 - 海量啊海量
设计:分层隔离
在 SOFARegistry 的应用场景中,体量庞大的数据主要有两类:Session 数据、服务信息数据。两类数据的相同之处在于其数据量都会不断扩展,而不同的是其扩展的原因并不相同:Session 是对应于 Client 的连接,其数据量是随着业务机器规模的扩展而增长,而服务信息数据量的增长是由 Publisher 的发布所决定。所以 SOFARegistry 通过分层设计,将两种数据隔离,从而使二者的扩容互不影响。
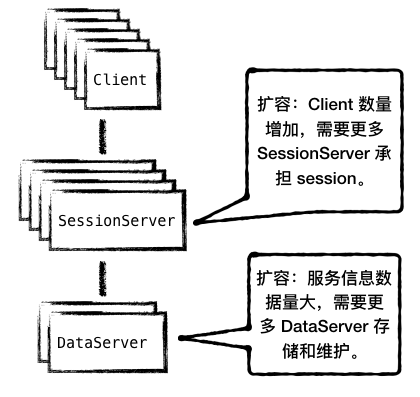
图3 - 分层,扩容互不影响
当然,对于分层设计的概念介绍,在《海量数据下的注册中心 - SOFARegistry 架构介绍》的 “如何支持海量客户端” 章节已经有了很完整的介绍,这里不再赘述。本文是想从代码层面来看看其设计实现的方式。
通信 Exchange
Exchange 作为 Client / Server 连接的抽象,负责节点之间的连接。在建立连接中,可以设置一系列应对不同任务的 handler (称之为 ChannelHandler),这些 ChannelHandler 有的作为 Listener 用来处理连接事件,有的作为 Processor 用来处理各种指定的事件,比如服务信息数据变化、Subscriber 注册等事件。
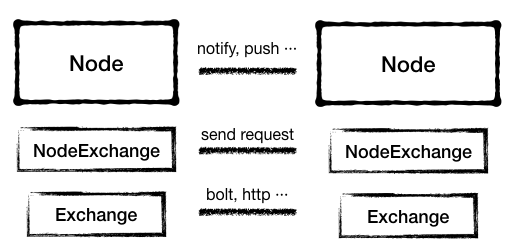
图4 - 每一层各司其职,协同实现节点通信
Session 节点在启动的时候,利用 Exchange 设置了一系列 ChannelHandler:
- PublisherHandler
- SubscriberHandler
- WatcherHandler
- ClientNodeConnectionHandler
- CancelAddressRequestHandler
- SyncConfigHandler
其中 SubscriberHandler 和 PublisherHandler 主要是与服务发布方 (Publisher) 以及服务调用方 (Subscriber) 的行为相关,我们在下面说明。
任务处理
由于 SubscriberHandler 在 Session 节点启动时就已经初始化并设置,所以当有 Subscriber 注册时,就由 SubscriberHandler 负责后续一系列的处理逻辑。
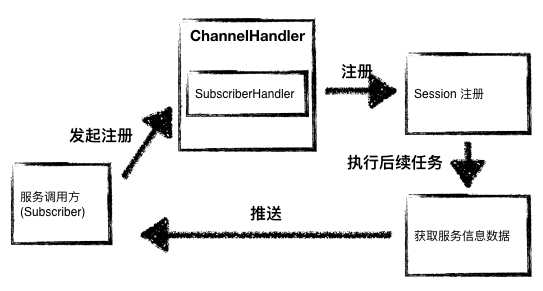
图5 - Subscriber 的注册过程
上面的流程图展示了 Subscriber 注册的处理过程,SessionSever 在处理注册请求时,除了保存 Subscriber 的会话信息,还要为新注册的 Subscriber 提供其所订阅的服务信息数据,最后通过推送的方式将数据发送 Subscriber。
下面是上述流程在代码模块上的实现,我们依然用图的方式展示出来,大家按图索骥也便于查阅相关源码中的细节。
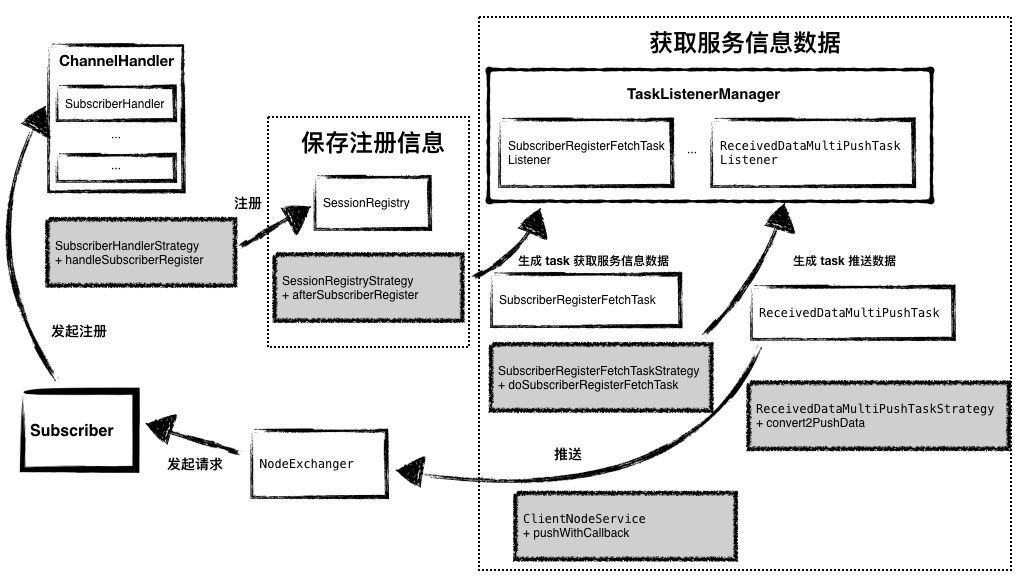
图6 - 代码流转:Subscriber 注册
可以看到,SOFARegistry 采用了 Handler - Task & Strategy - Listener 的方式来应对服务注册中的各种场景和任务,这样的处理模型能够尽可能的让代码和架构清晰整洁。
Publisher 的注册过程和 Subscriber 基本一致,略有不同的是 Publisher 在注册完毕之后将要发布的数据写到 DataServer 上。
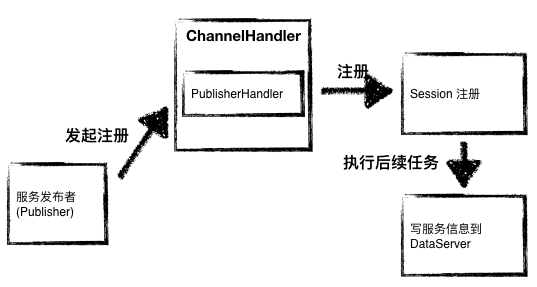
图7 - Publisher 的注册过程
这个过程也是采用了 Handler - Task & Strategy - Listener 的方式来处理,任务在代码内部的处理流程和订阅过程基本一致。
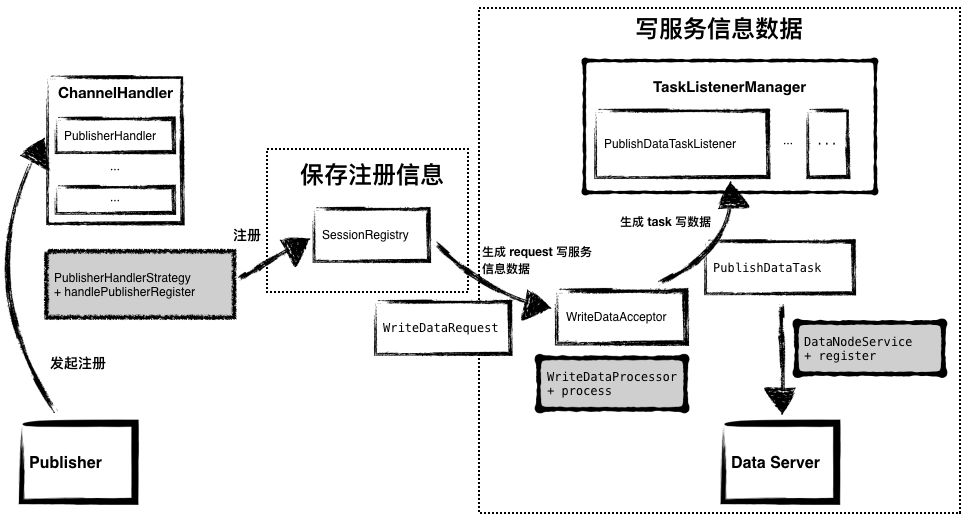
图8 - 代码流转:Publisher 注册
会话缓存
在二层架构中 (即 Client 直接连接 DataServer),连接数是一个很难收敛的指标,因为当一个 Subscriber 订阅的服务位于不同 DataServer 上时,他就会与多个 DataServer 同时保持连接,这样“每台 DataServer 承载的连接数会随 Client 数量的增长而增长,每台 Client 极端的情况下需要与每台 DataServer 都建连,因此通过 DataServer 的扩容并不能线性的分摊 Client 连接数”。
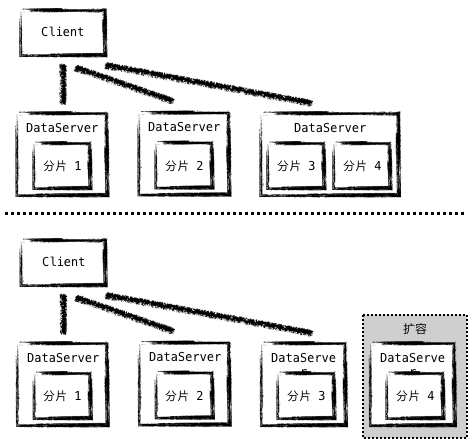
图9 - 两层结构中,扩容无法减少连接数
这也是 SOFARegistry 设计三层模型的原因,通过 SessionServer 来负责与 Client 的连接,将每个 Client 的连接数收敛到 1,这样当 Client 数量增长时,只需要扩容 SessionServer 集群就可以了。 所以从设计初衷上我们就能够看出来 SessionServer 必须要满足的两个主要能力:从 DataServer 获取服务信息数据;以及保存与 Client 的会话。下面我们分开来谈:
1. 从 DataServer 获取服务信息数据;
其实很好理解,既然 SessionServer 扮演了三层结构中的“中间商”角色,那它也就理应替 Subscriber 从 DataServer 获取数据。但是这里有一个考量:SessionServer 要不要缓存数据,以及如何缓存从 DataServer 获取的数据。
- SessionServer 要不要缓存数据?
服务信息数据从 SessionServer 被推送到 Subscriber 主要有两种触发场景:一是 DataServer 上的数据有变化,二是有新的 Subscriber 注册到 SessionServer。两种场景的出现频率是不一样的,在实际应用中第二种场景才是数据推送的主要原因,所以 SessionServer 上缓存数据可以对 DataServer 层屏蔽 Client 的变化,从而有效减轻 DataServer 的压力。
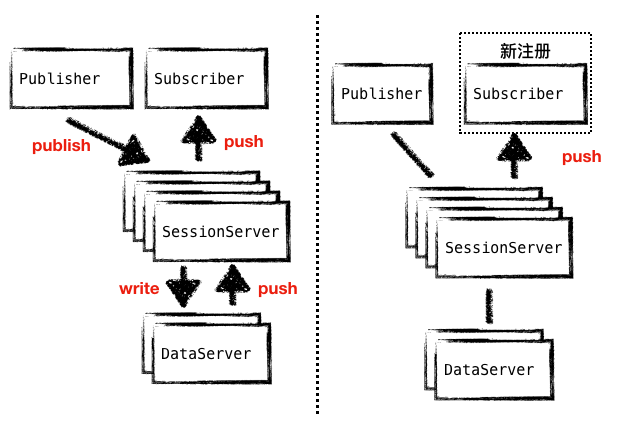
图10 - 两种场景导致的数据推送
- 如何缓存从 DataServer 获取的数据?
这里 SOFARegistry 采用了 LoadingCache的数据结构,通过给 cache 中的 entry 设置过期时间的方式,使得 cache 定期从 DataServer 中拉取数据以替换过期的 entry。同时,当 DataServer 中有数据更新时,也会主动向 SessionServer 发请求使对应 entry 失效,从而促使 SessionServer 去更新失效 entry。具体细节如图所示:
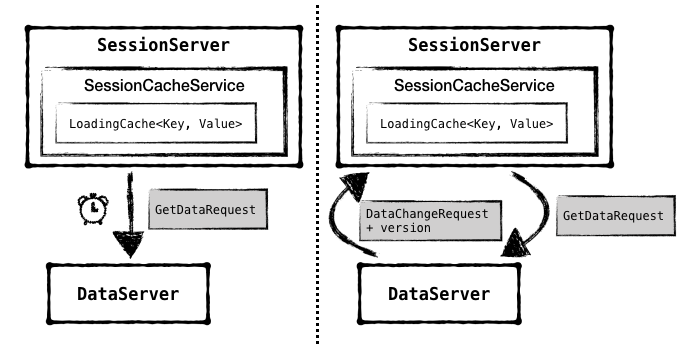
图11 - SessionServer 从 DataServer 更新数据
在代码实现中,依然是采用 Handler - Task & Strategy - Listener 的方式来处理,感兴趣的读者可以实际翻阅代码查看具体细节。
2. 保存与 Client 的会话
每个 SessionServer 都负责与若干 Client 的连接,所以在 SessionServer 中也会有专门的数据结构来保存这些会话。随着 Client 数量增加,我们可以通过扩容 SessionServer 集群的方式来解决 SessionServer 连接数增加的。

图12 - SessionInterests 维护 Client 的连接
如图中所示,SessionServer 会分别用不同的数据结构来保存 Subscriber 和 Publisher 的会话,这种设计的一个重要原因是 SessionServer 会定期与 DataServer 进行 Publisher 的数据比对,以保证数据的一致性。这方面的细节我们会在后续的文章中继续讨论。
总结
SOFARegistry 作为服务注册中心,需要面对的业务场景以及要处理的任务种类都比较多,其代码也涉及到分布式存储、一致性算法、会话连接等多个方面,可以算是架构设计方面一本很好的“教材”。本文从 Session 存储的角度出发,剖析了 SessionServer 在实现过程中的一些设计思路和代码抽象,希望可以对读者的学习有所帮助和启发。