Mybatis二级缓存
目录
一、简介
我们平时开发中为了减轻数据库的访问压力都会用到缓存,在写少读多的场景下能有效的改善程序性能以及减少数据库的压力,Mybatis的缓存自然也是出于这个目的,在读数据库后将结果放入缓存中,下一次读取缓存命中了就直接返回不需要再读库了,在修改操作的时候清空掉缓存
什么是二级缓存?
顾名思义就是有两层缓存,缓存的范围不一样:
- 一级缓存是针对SqlSession,可以理解为是一个连接(同一个数据库连接下执行的查询共用一块缓存)
- 二级缓存是针对namespace,也就是一个Mapper.xml文件,一个文件内的查询共用一块缓存,多个namespace缓存之间相互不受影响
一级缓存默认开启,二级缓存默认是关闭的
为什么要搞二级缓存?
从上述可以明显的看到二级缓存是对一级缓存的一个优化,毕竟一个连接的作用域有啥用,连接用完就关了,缓存时效性太差,而采用二级缓存后缓存能在多个连接之间共享,这命中率不大大提升
为什么不采用全局缓存?
虽然全局缓存在命中率方面比二级缓存更有优势,但是数据库有那么多的表,假设我已经缓存很多查询了,就因为你某个表要修改,就全删除吗?这合理吗?那是不是只需要删除跟这个被修改的表有关的缓存数据就可以了,仔细想想这不就是二级缓存?平时开发习惯一个namespace不就是针对一个表的?
二、一级缓存
1.入口
既然是跟查询有关那肯定是在执行器里面,所以是在最底层的BaseExecutor里面
BaseExecutor.query
这个localCache就是一级缓存,针对SqlSession所做的缓存
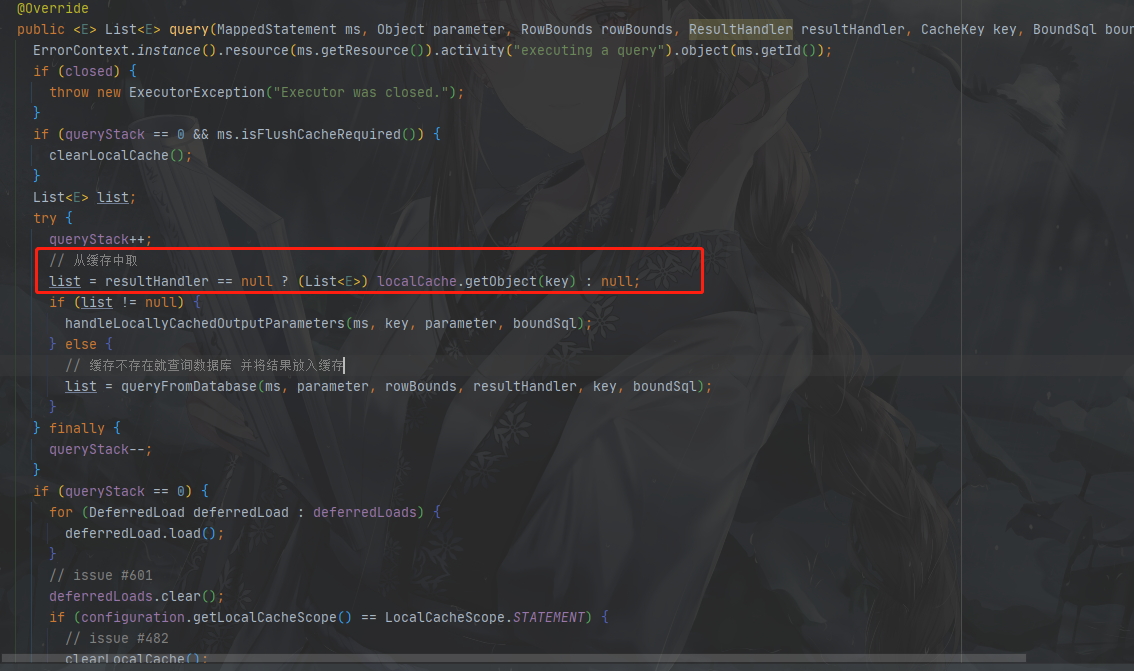
一级缓存的缓存类是PerpetualCache(也就是上述的localCache),如下:
内部有一个HashMap来存储结果

2.演示
我们先在上述缓存前后加上一些输出来观察缓存的变化:
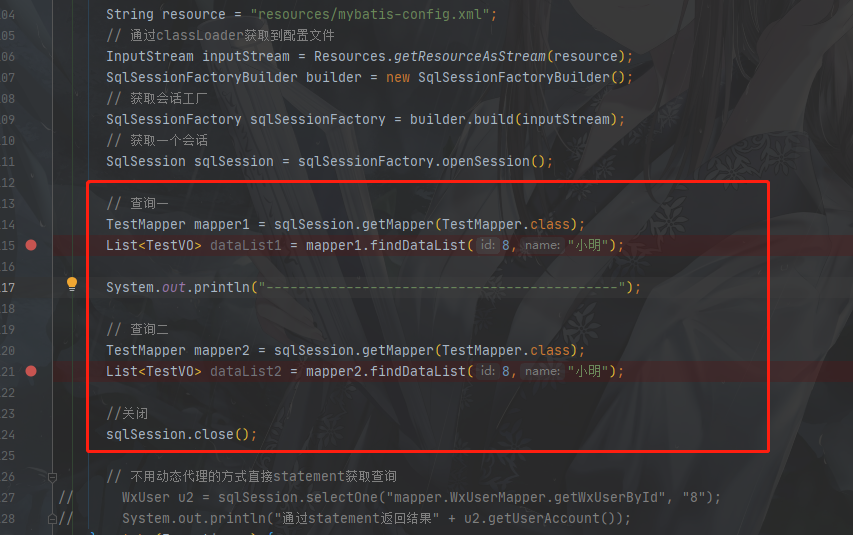
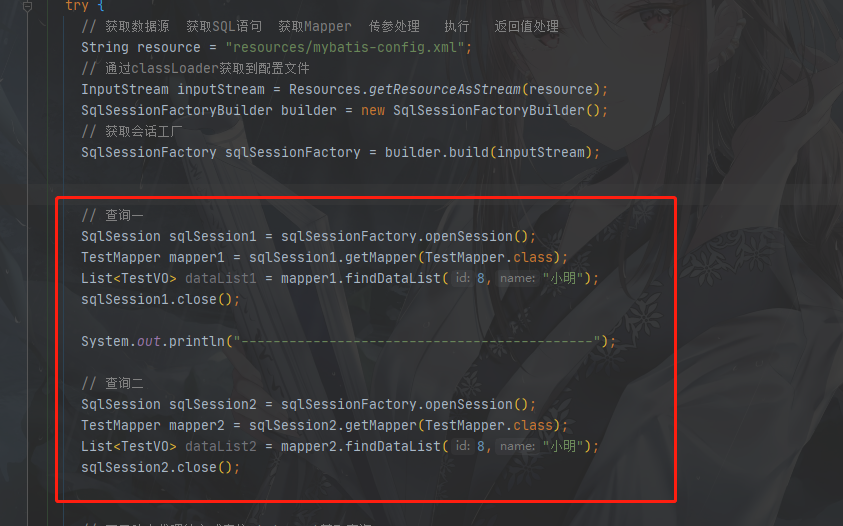
案例一:
我们在同一个SqlSession整两个一样的查询,并用分隔符分开,执行查看结果
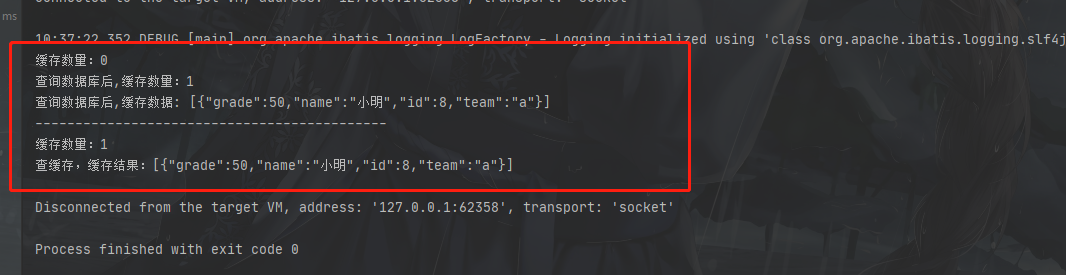
结果:
看分割线上是第一次查询,所以开始缓存数量为0,之后缓存数量为1,并缓存了一条数据,第二次查询直接就命中了缓存并返回了结果
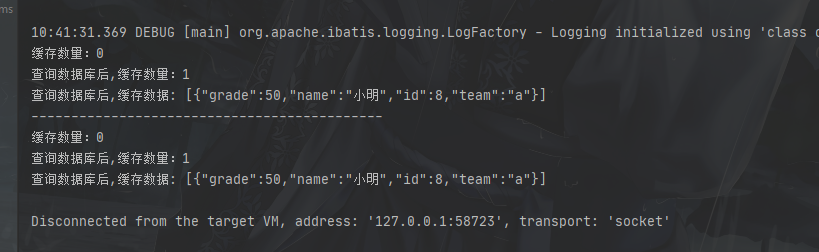
案例二:
我们两个查询分别用了不同的SqlSession,再看看结果
结果:
两次查询的缓存是相互隔离的
3.总结
由此可见,一级缓存仅在SqlSession中,不同的SqlSession缓存是互不干扰的,所以效果微乎及微
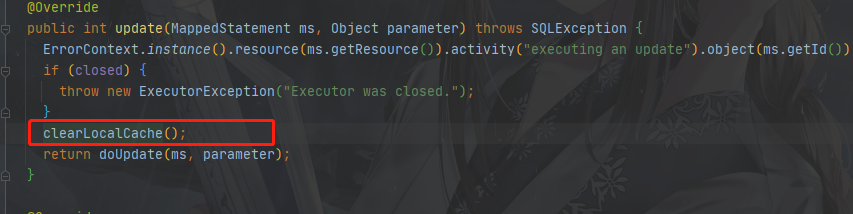
什么时候删除?
同样在BaseExecutor中做新增、修改、删除操作的时候就会清空当前SqlSession中的缓存,如:
三、二级缓存
1.入口
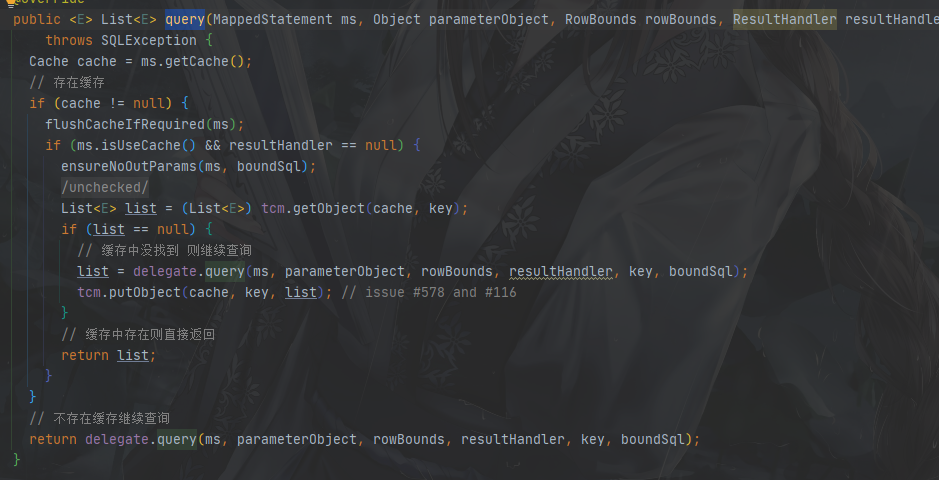
与上述一样,一样是在执行器里面,但是这个执行器有点特殊,专门用来做二级缓存用的,那就是CachingExecutor.query
而且这个执行器在默认情况下一定会走,因为在开始选择执行器的时候判断了,默认的参数为true
如下:

既然一定会走,为什么又说二级缓存默认关闭呢?
在上述执行过程中可以看到,会先从MapperStatement中获取一个Cache对象,该对象不为空才会走缓存,该对象为null ,就会走数据库查询了,所以在二级缓存没开启的情况下是获取不到这个对象的,所以自然会走数据库了
2.如何开启二级缓存
在我们解析的过程中可以发现有个关于cache的配置加载,这两个是干嘛的?
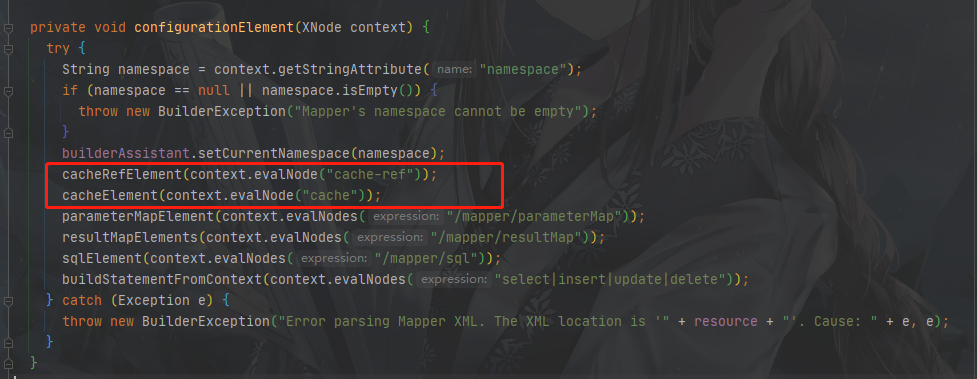
cache-ref配置
我们之前说过二级缓存的作用域是namespace,每个namespace之间是独立的,但有的时候我就是想共享怎么办?总不能全写到一个namespace中吧,所以cache-ref的作用就是可以指定和某个namespace共享缓存
<cache-ref namespace="com.xxxx.xxxx.XxxxxMapper"/>
cache配置
既然二级缓存在每个namespace之间是独立的,所以每个namespace是可以独立选择开启或者关闭的,开关就是cache配置,同时还附带有几种属性可以来配置缓存,如下:
<cache
eviction="LRU"
flushInterval="60000"
size="1024"
readOnly="true"/>
cache标签代表为这个namespace开启二级缓存。其他属性分别有其作用,可自由组合配置:
- eviction: 缓存清除策略,有以下几种,默认是LRU
- LRU – 最近最少使用:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
- WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
- flushInterval: 刷新间隔,以毫秒为单位,时间到了就会在调用语句的时候清空缓存。默认不刷新
- size: 缓存的数量(默认1024)
- readOnly: 只能设置成true或者false。true的情况下缓存返回的数据对象不能被修改,false的情况下会返回缓存对象的拷贝。默认值是false
3.针对某查询禁用二级缓存
开启二级缓存后,namespace下的查询语句默认都会缓存,要是某个查询我不想缓存呢?
可以设置该查询useCache属性为false,默认是true
<select id="findUserById" ...... useCache="false">
SELECT * FROM user WHERE id = #{id}
</select>
4.控制二级缓存刷新
在不设置缓存刷新时间,默认情况下查询不会刷新缓存,新增、删除、更新都是刷新缓存
可以设置flushCache属性,true是刷新缓存,false是不刷新缓存
<select id="findUserById" ...... flushCache="true">
SELECT * FROM user WHERE id = #{id}
</select>
5.自定义缓存
我们所使用的缓存都是某个缓存类,我也可以自定义实现自己的一个缓存类,或者采用第三方的缓存方案,要实现我们自己的缓存类,我们只需要实现org.apache.ibatis.cache.Cache 接口,且提供一个接受 String 参数作为 id 的构造器,并在cache标签中指定自己的缓存类,如下:
<cache type="com.xxxx.xxxx.MyCache"/>
四、缓存执行顺序
同样的我们在二级缓存处也做一些输出处理
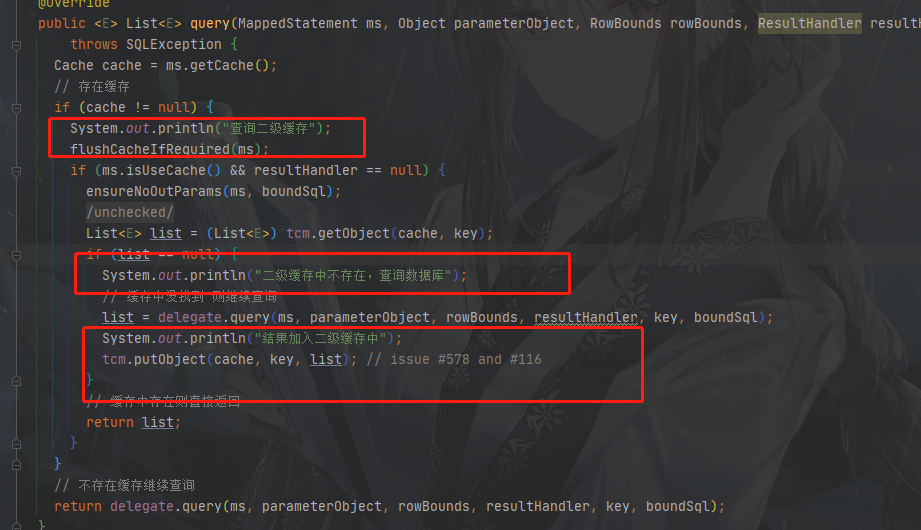
案例一:
我们在一个SqlSession中放了三个一样的查询
结果:
执行顺序是先二级再一级没错,但是你会发现之后的查询依旧没走二级缓存而是走了一级缓存,表示二级缓存中没查到
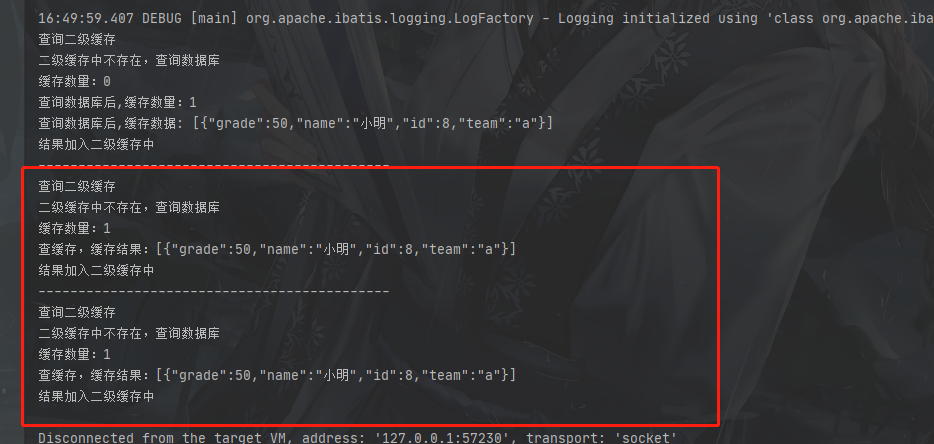
为啥会这样?不是都放进缓存了吗?
二级缓存不是有结果后立刻存储的,而是在事务commit之后才会存储,所以查不到
案例二:
与上面相反用了两个SqlSession
结果:
很明显第二个查询走了二级缓存,这也正好印证了上面我们说的
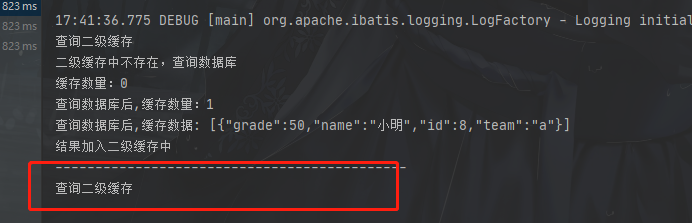
缓存执行顺序:
二级缓存→一级缓存→数据库
五、总结
- 一级缓存在BaseExecutor中,作用域是SqlSession
- 二级缓存在CachingExecutor中,作用域是namespace
- 两者都会在修改操作时删除缓存,事务回滚时清除缓存
- 执行顺序为:二级缓存→一级缓存→数据库
- 一级缓存默认开启,二级缓存默认关闭
缓存虽好,但也有利有弊,有什么坏处?
一级缓存我们可能平时不会在意,反正即用即删了,但二级缓存一旦开启就得注意了,因为namespace之间是独立的,然后平时使用多服务下,服务之间又是独立的,用不好就会导致数据不一致,建议慎用!