Redis 数据结构源码浅析
作者:蒋弘毅 | 研发后端
来源:有赞coder
注:本文介绍的源码为redis 5.0.14版本
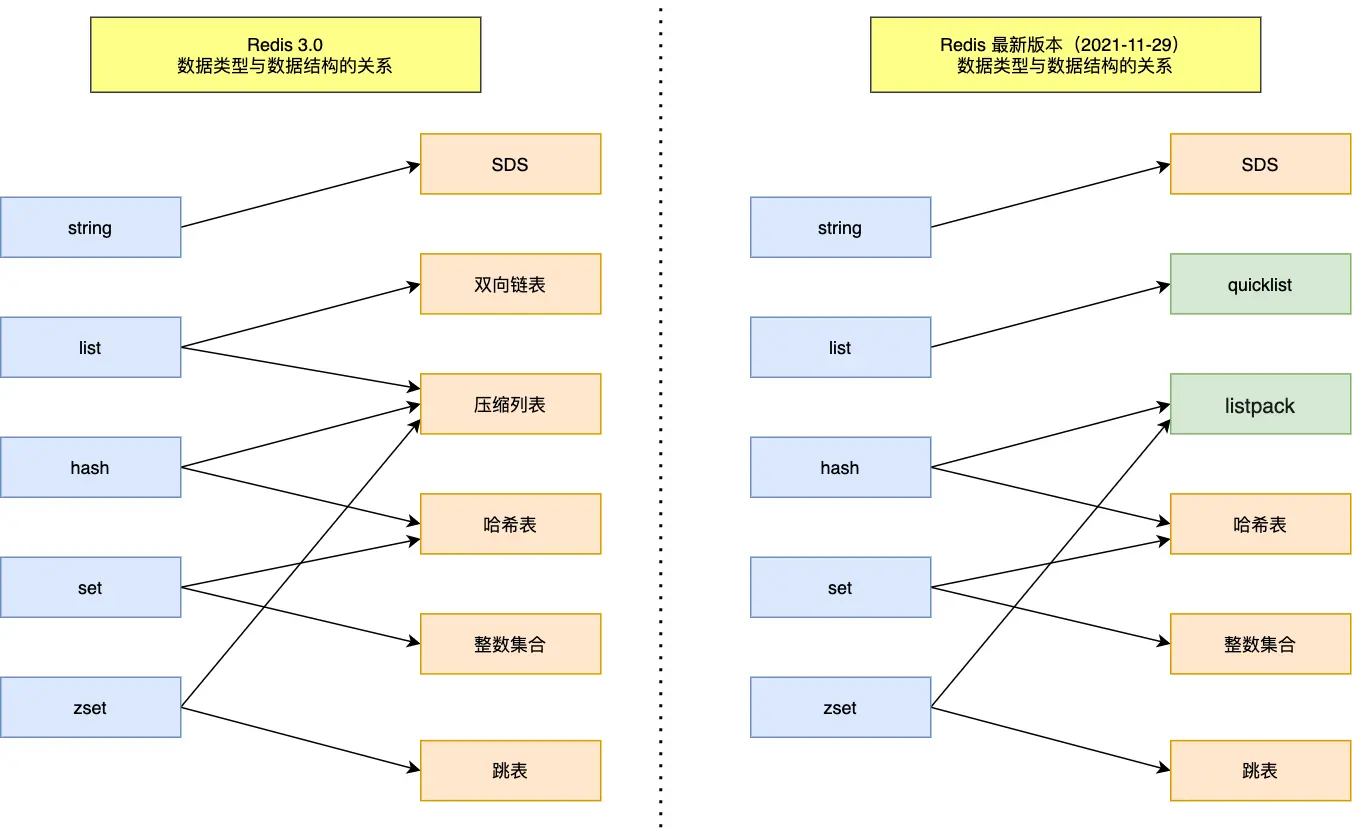
字符串
C语言存储字符串的问题
- 二进制安全
C语言中表示字符串结尾的符号是'\0',如果字符串本身就具有'\0'字符,就会被截断,即非二进制安全。
计算字符串的长度性能低
C语言中有一个计算字符串长度的函数strlen,但这个函数与Java的不一样,需要遍历整个字符串来计算长度,时间复杂度是O(n),如果需要在循环中计算,性能将十分低下。
字符串拼接性能低
因为C语言字符串不记录长度,对于一个长度n的字符串来说,底层是n+1的字符数组。
char a[n+1]
如果需要增长字符串,则需要对底层的字符数组进行重分配的操作;接下来由数据结构入手,看看redis是如何解决这几个问题的。
redis数据结构
struct sds{
int len; //buf中已占字符数
int free; //buf中空闲字符数
char buf[];
}
除了保存字符串的指针buf,还需要记录使用空间和空闲的空间。redis老版本也是这样设计的,这样的设计解决了开头的三个问题:
- 计算字符串长度的时候,时间复杂度是O(1)
- 使用len变量得出字符串的长度,而不是’\0‘,保证了二进制安全
- 对于字符串的拼接操作,进行预分配空间,减少内存重分配的次数
小字符串空间浪费的问题
在64位系统中,字符串头部的len和free各占四个字节,对于大字符串而言,这个数字还好,但是如果是小字符串呢,比如buf本身只有一个字节,而头部就占了八个字节,肯定不合适。
redis新版本就给了一种方案,根据buf字符串的长度不同,使用不同的结构体存储,同时新增一个单字节变量flags,保存不同的类型。
但是对于那种只有一个字节长的字符串,如何优化呢?对于那种小字符串,redis中使用一个字节的标志位flags表示 低三位存储类型(type),高五位存储长度(len),而高五位 2^5-1=31 可以存储最多31个字节的字符串。
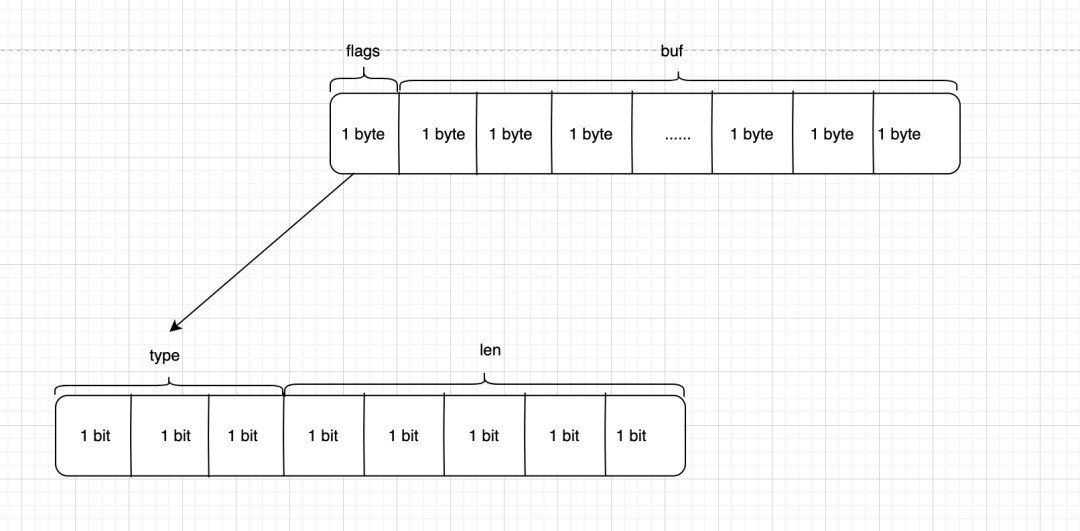
而大于31个字节的其他几种类型字符串,一个字节存不下,就使用两个变量保存已使用空间和总长度(保留flags字段标识类型,新增len字段标记长度)。
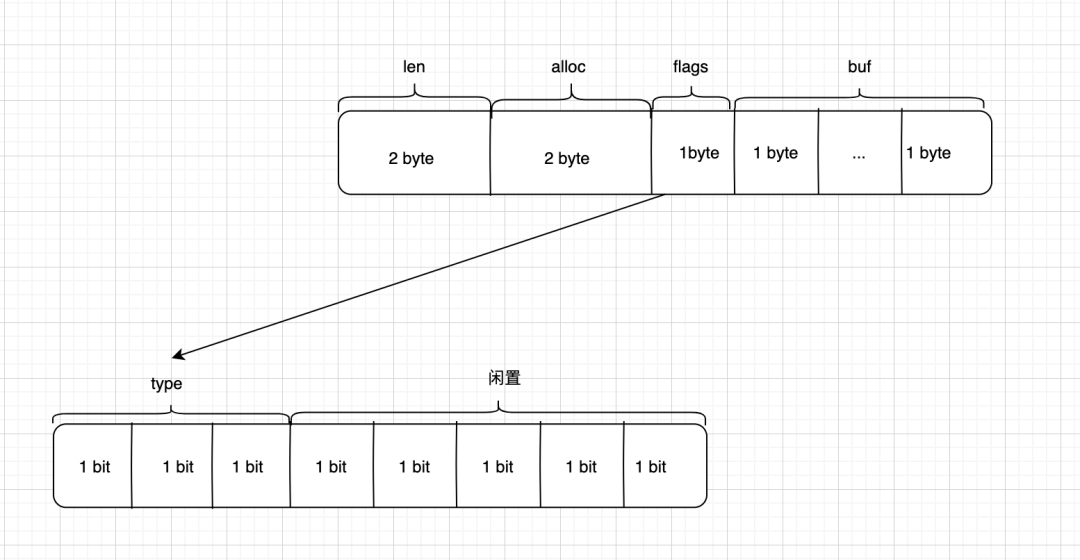
sdshdr8,sdshdr16,sdshdr32,sdshdr64 结构都是一样的,区别在于存储的变量大小。
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; //已使用
uint8_t alloc; // 总长度
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
基本操作
只介绍扩容操作,其它操作都比较简单,可自行阅读。
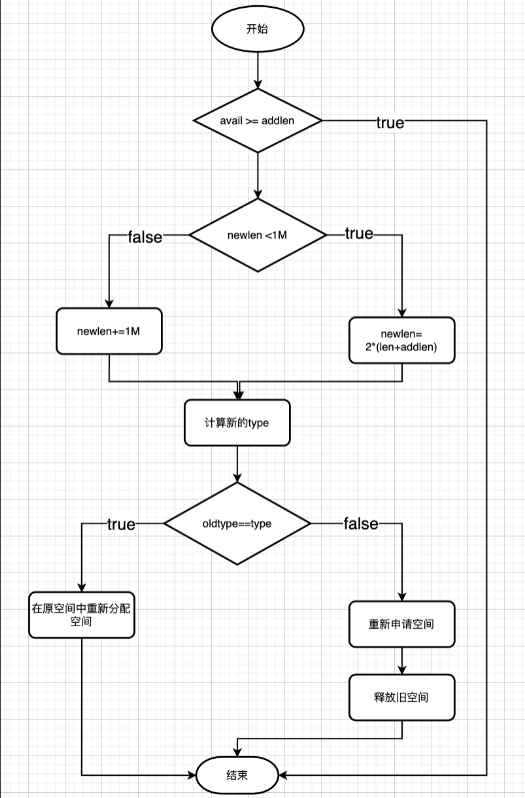
扩容源码如下:
sds sdsMakeRoomFor(sds s, size_t addlen) {
struct sdshdr *sh, *newsh; //定义两个 sdshdr 结构体指针
size_t free = sdsavail(s); // 获取 s 目前空闲空间长度
size_t len, newlen; // 前者存储扩展前 sds 字符串长度,后者存储扩展后 sds 字符串长度
if (free >= addlen) return s; // 如果空余空间足够,直接返回
len = sdslen(s); // 获取 s 目前已占用空间的长度
sh = (void*) (s-(sizeof(struct sdshdr))); //结构体指针赋值
newlen = (len+addlen); // 字符串数组 s 最少需要的长度
// 根据新长度,为 s 分配新空间所需的大小
if (newlen < SDS_MAX_PREALLOC) // 如果新长度小于 SDS_MAX_PREALLOC(默认1M),那么为它分配两倍于所需长度的空间
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC; // 否则,分配长度等于目前长度加上 SDS_MAX_PREALLOC(默认1M)
newsh = zrealloc(sh, sizeof(struct sdshdr)+newlen+1);
if (newsh == NULL) return NULL;
newsh->free = newlen - len;
return newsh->buf;
}
跳跃表
一个例子
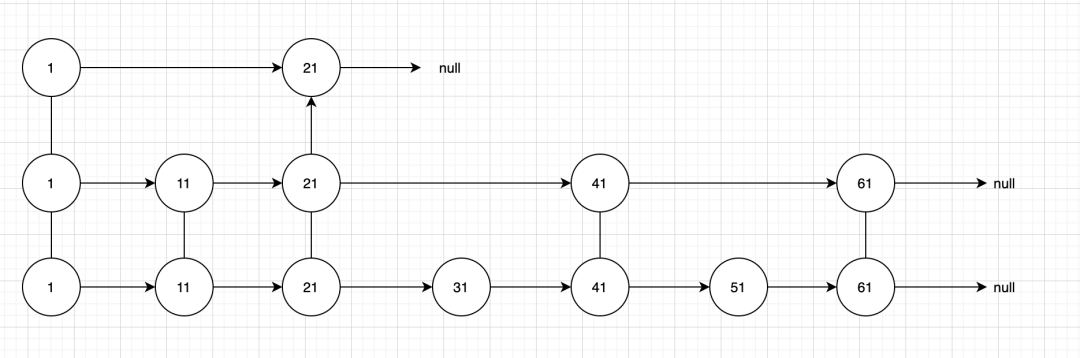
例如查找51这个数:
- 首先从第一层开始查找,找到第二个节点,发现后面为null
- 从第二层查找 查找到第四个节点,发现后面的节点为61,大于当前的数
- 从第三层查找 查找到第六个节点 结束 一共查找四次,比遍历一次少了两次。数据量大的情况下,这个性能会提升的很明显
跳跃表结构
首先看一下zskiplistNode的数据结构,zskiplistNode表示跳跃表中的一个节点。
typedef struct zskiplistNode {
sds ele;// 数据
double score; //权重比
struct zskiplistNode *backward; //后退指针,指向当前节点底层 前一个节点
struct zskiplistLevel {
struct zskiplistNode *forward; // 指向当前层的前一个节点
unsigned long span; //forward 指向前一个节点的与当前节点的间距
} level[];
} zskiplistNode;
zskiplist 表示跳跃表:
typedef struct zskiplist {
struct zskiplistNode *header, *tail; //分别指向头结点和尾结点
unsigned long length; //跳跃表总长度
int level; //跳跃表总高度
} zskiplist;
其中,头节点是跳跃表的一个特殊节点,它的level数组元素个数为64。头节点在有序集合中不存储任何member和score值,ele值为NULL, score值为0;也不计入跳跃表的总长度。头节点在初始化时,64个元素的forward都指向NULL, span值都为0。
基本操作
创建跳跃表
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
// 头结点
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
简单来说就是创建了头结点,创建了64个level数组。(层高为32或者64因版本有差异)
随机层高
创建和插入节点的之前,当前节点需要在哪几层出现,是通过计算当前节点的level值, 而level值是redis通过伪随机得出的,层数越高,节点出现的概率越小。
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
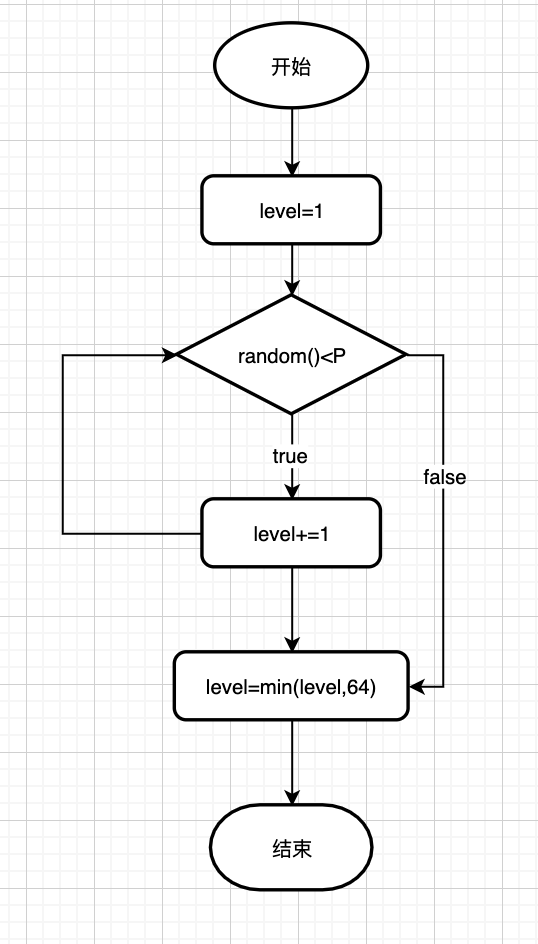
层高的数学期望:
高度为1的概率 (1-p)
高度为2的概率 p(1-p)
高度为3的概率 (p2) *(1-p)
….
高度为n的概率(p(n-1)) *(1-p)
期望层高 E=1 *(1-p)+2p(1-p)+3p2(1-p)... =1/(1-p)
当 p=0.25(redis默认值) 时,跳跃表节点的期望层高为 1/(1-0.25)≈1.33。即多浪费了30%的空间,redis的跳表使用了较低的空间成本,实现了时间复杂度的大减少
插入节点
插入节点总的来说一共四步
- 查找插入位置
- 调整高度
- 插入节点
- 调整backward
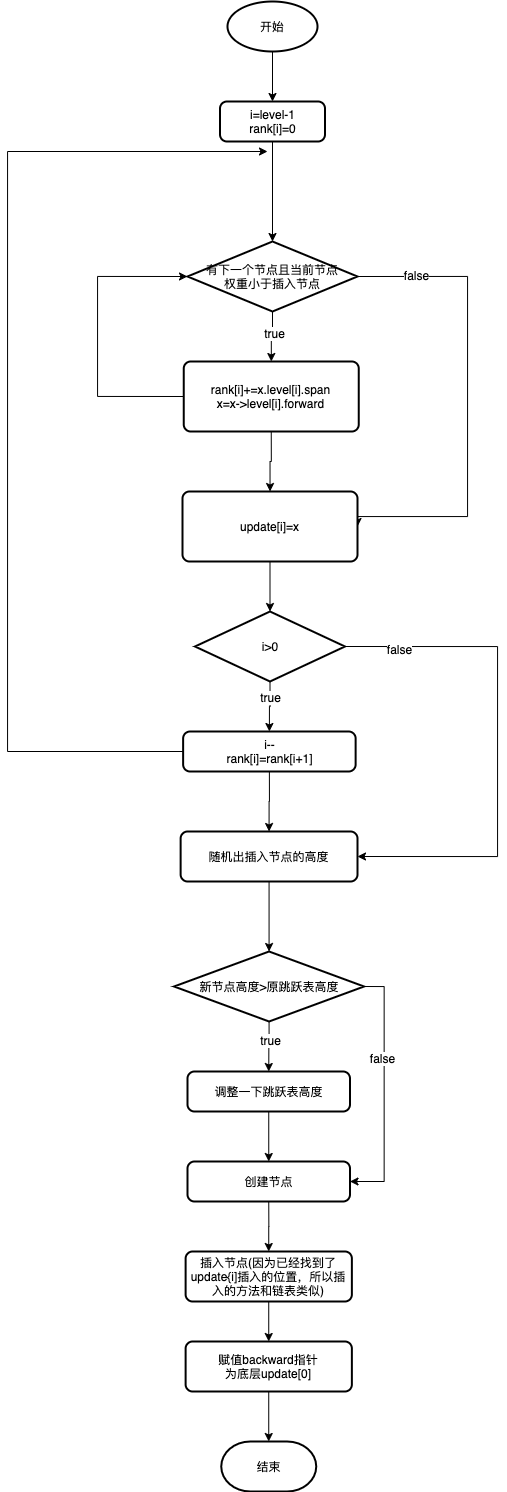
源码如下:
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
// 查找节点
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
//调整高度
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
//插入节点
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
删除节点
- 查找节点 (同插入节点)
- 删除节点
- 修改高度
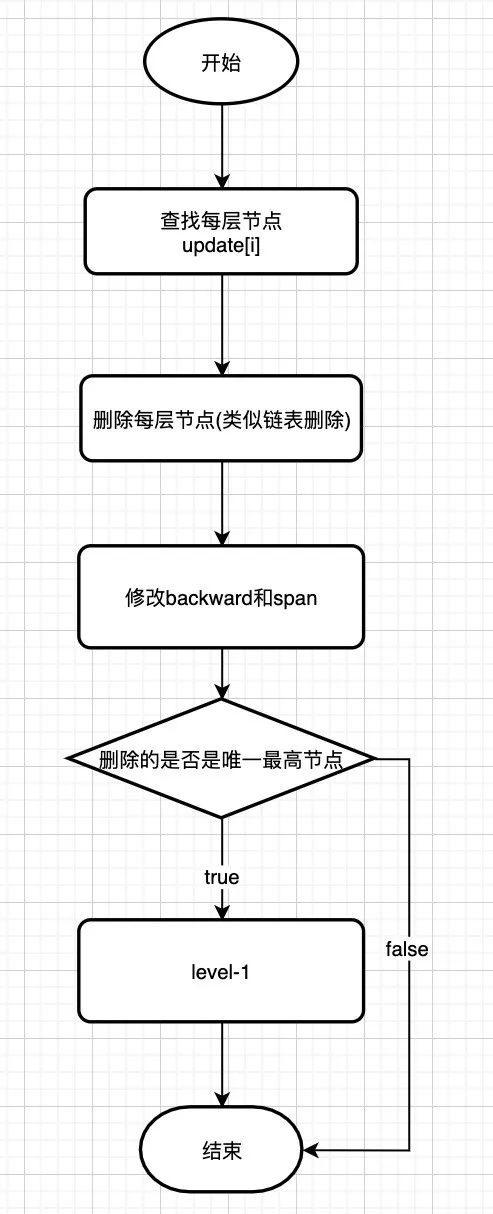
源码如下:
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) { // update[i].level[i] 的 forward 节点是 x 的情况,需要更新 span 和 forward
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {// update[i].level[i] 的 forward 节点不是 x 的情况,只需要更新 span
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) { // 如果 x 不是尾节点,更新 backward 节点
x->level[0].forward->backward = x->backward;
} else { // 否则 更新尾节点
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--; //更新跳跃表 level
zsl->length--; // 更新跳跃表长度
}
跳跃表的应用
zset集合插入第一个元素时,会判断下面两种条件:
- zset-max-ziplist-entries 的值是否等于 0
- zset-max-ziplist-value 小于要插入元素的字符串长度
满足任一条件 Redis 就会采用跳跃表作为底层实现,否则采用压缩列表作为底层实现方式。
为什么redis使用跳跃表而不是红黑树呢
- 这并不会浪费太多的空间,并且树的高度可以动态调整的。
- ZRANGE 和 ZREVRANGE命令,跳表性能比红黑树好
- 红黑树比较复杂...作者懒得实现
整数集合
整数集合(intset)是一个有序的、存储整型数据的结构。
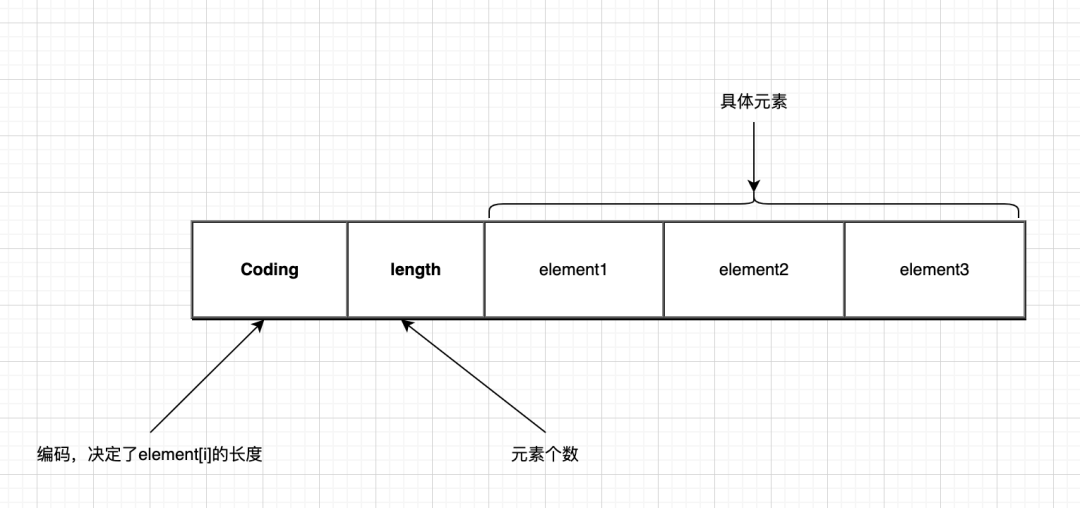
conding决定了的element的长度,对应关系如下:

基本数据结构
typedef struct intset {
//编码
uint32_t encoding;
//元素个数
uint32_t length;
// 柔性数组,根据encoding 决定几个字节表示一个数组
int8_t contents[];
} intset;
基本操作
查询元素
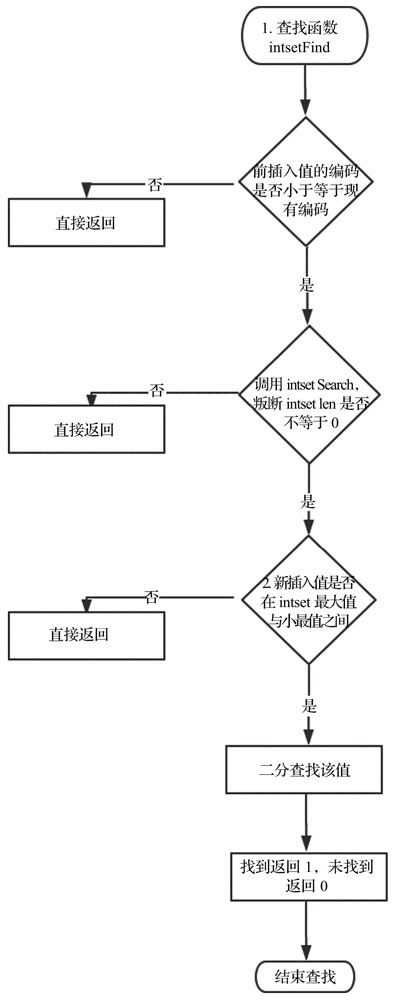
源码如下:
uint8_t intsetFind(intset *is, int64_t value) {
uint8_t valenc = _intsetValueEncoding(value); //判断编码方式
//编码方式如果大于当前intset的编码方式,直接返回0。否则调用intsetSearch函数进行查找
return valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,NULL);
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
/*如果intset中没有元素,直接返回0 */
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0;
return 0;
} else {
/* 如果元素大于最大值或者小于最小值,直接返回0 */
if (value > _intsetGet(is,max)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
} else if (value < _intsetGet(is,0)) {
if (pos) *pos = 0;
return 0;
}
}
while(max >= min) { //二分查找该元素
mid = ((unsigned int)min + (unsigned int)max) >> 1;
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) { //查找到返回1,未查找到返回0
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
}
}
插入元素
插入元素比较简单,不再赘述源代码,感兴趣的同学可以查看方法。
删除元素
删除元素比较简单,不再赘述源代码,感兴趣的同学可以查看方法。
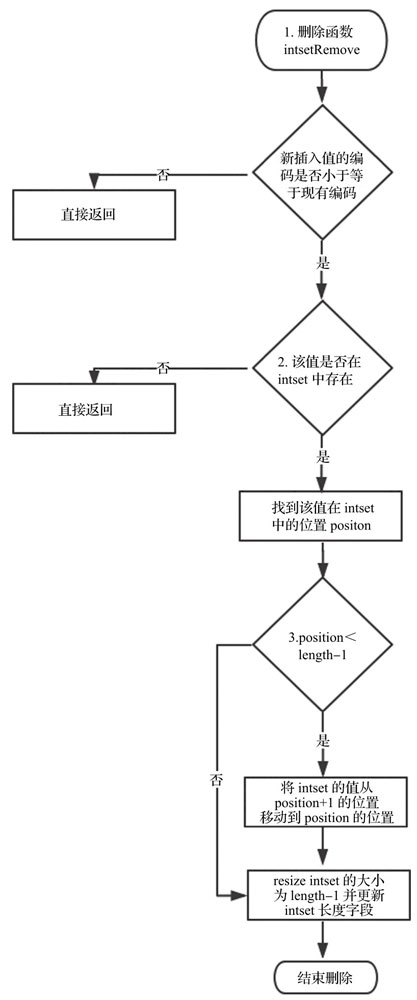
应用场景
当Redis集合类型的元素都是整数并且都处在64位有符号整数范围之内时,使用该结构体存储。
在两种情况下,底层编码会发生转换:
- 一种情况为当元素个数超过一定数量之后(默认值为512),即使元素类型仍然是整型,也会将编码转换为hashtable。
- 往集合中添加了非整型变量
字典
字典底层类似Java的HashMap,但是扩容的方式有一定的区别。
基本数据结构
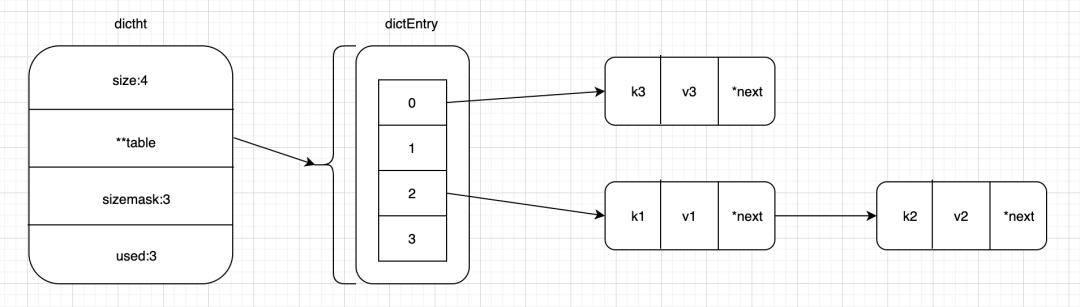
哈希表:
typedef struct dictht {
// 二维数组
dictEntry **table;
// table总大小
unsigned long size;
// 掩码=size-1
unsigned long sizemask;
// 已经保存的键值对
unsigned long used;
} dictht;
二维数组中的键值对:
typedef struct dictEntry {
//键
void *key;
//值
union {
void *val; //值
uint64_t u64;
int64_t s64; //过期时间
double d;
} v;
// hash冲突的next指针
struct dictEntry *next;
} dictEntry;
字典,使用Hash表包了一层:
typedef struct dict {
//操作类型
dictType *type;
// 依赖的数据
void *privdata;
// Hash表
dictht ht[2];
// -1代表没有进行rehash值,否则代表hash操作进行到了哪个索引
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 当前运行的迭代器数
unsigned long iterators; /* number of iterators currently running */
} dict;
基本操作
添加元素
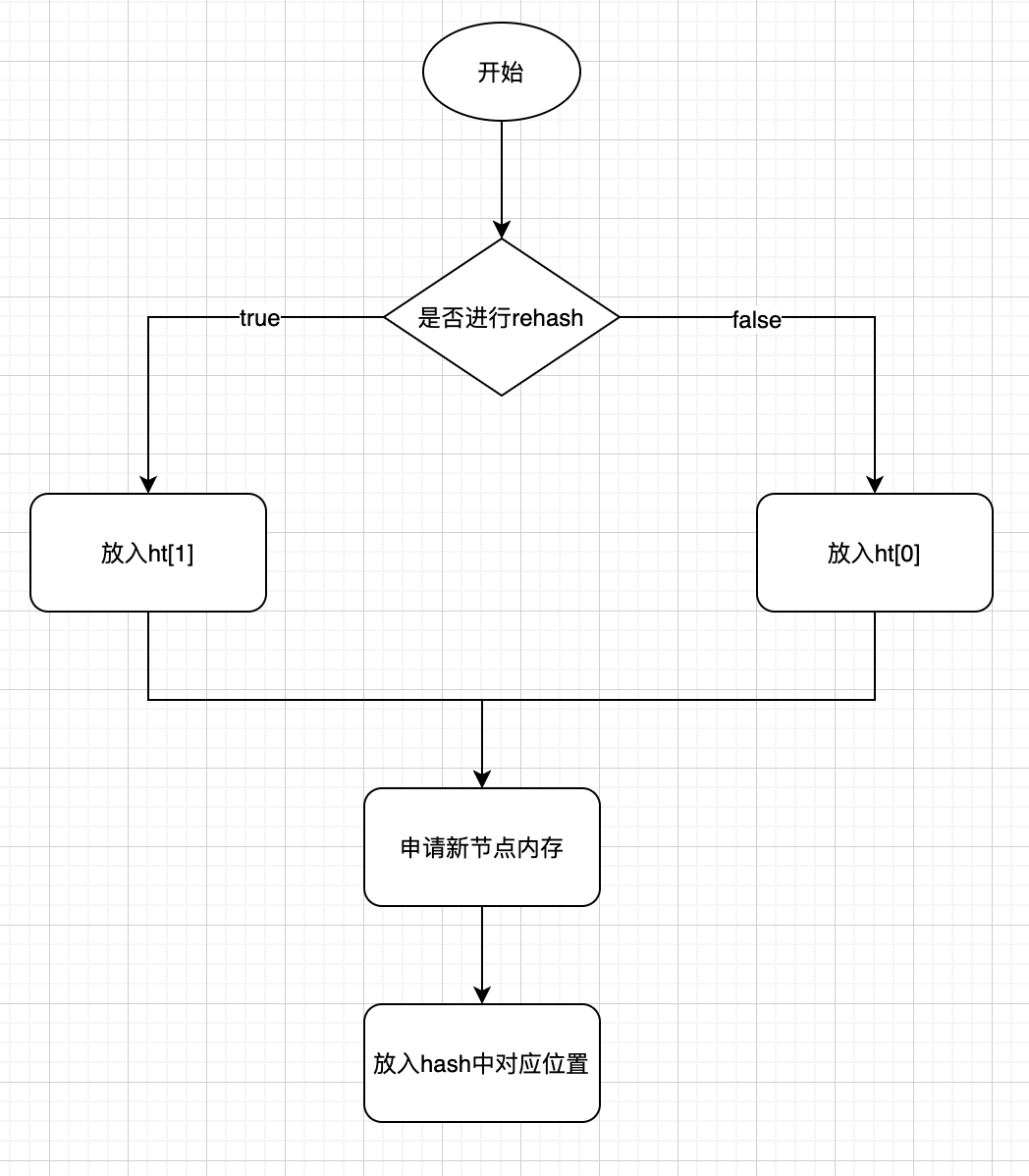
源码如下:
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing) /* 入参字典、键、Hash 表节点地址 */
{
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); /* 该字典是否在进行 rehash 操作,是则执行一次 rehash */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) /* 查找键,找到则直接返回 -1,并把老节点存入 existing 字段,否则把新节点的索引值返回。如果遇到 Hash 表容量不足,则进行扩容 */
return NULL;
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; /* 是否在进行 rehash 操作中,是则插入至散列表 ht[1] 中,否则插入散列表 ht[0] */
entry = zmalloc(sizeof(*entry)); /* 申请新节点内存 */
entry->next = ht->table[index]; /* 将该节点的 next 指针指向 ht->table[index] 指针指向的位置 */
ht->table[index] = entry; /* 将 ht->table[index] 指针指向该节点 */
ht->used++;
dictSetKey(d, entry, key); /* 给新节点存入键信息 */
return entry;
}
其中查找元素的代码:
dictHashKey(d,key), existing)// 根据字典的hash函数得到key的hash值
idx = hash & d->ht[table].sizemask; //利用key的hash值与掩码进行与操作(因为与操作的速度比取余快,也就是为什么要存一个掩码)
扩容
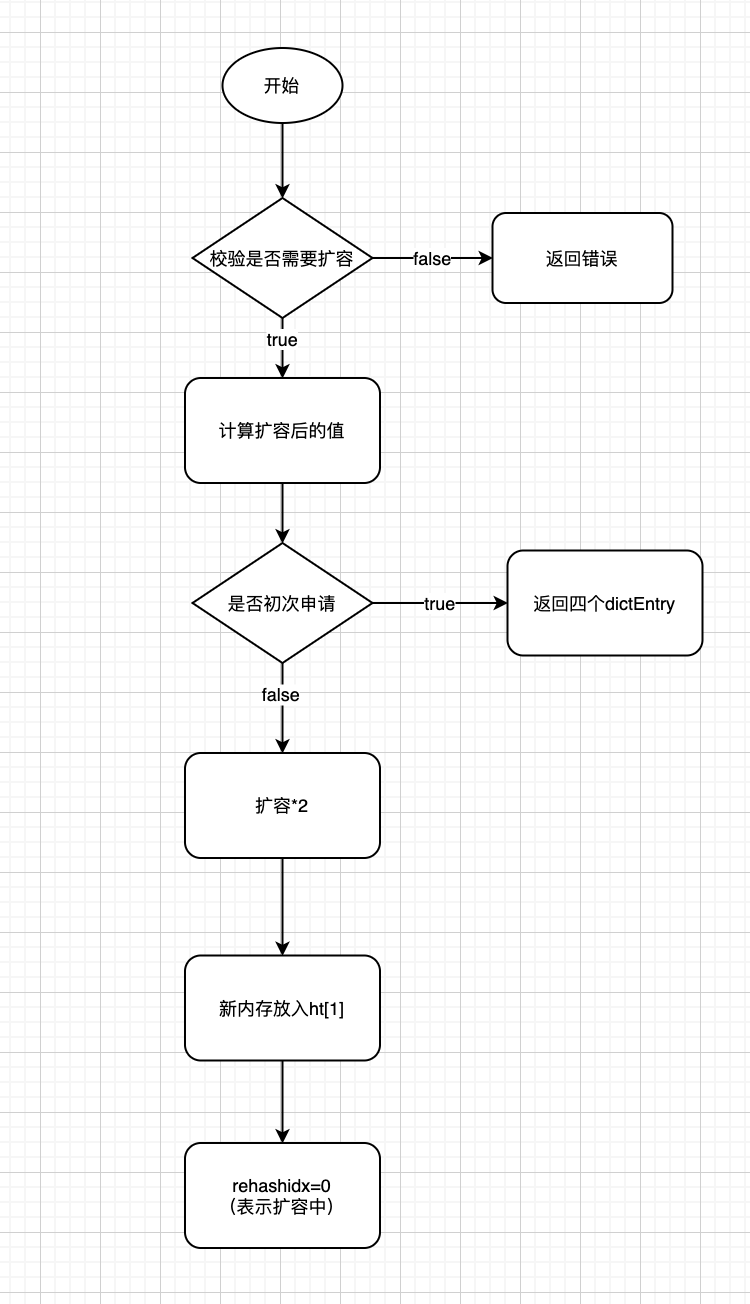
源码如下:
int dictExpand(dict *d, unsigned long size)
{
if (dictIsRehashing(d) || d->ht[0].used > size) /* 如果此时正在扩容,或者是扩容大小小于 ht[0] 的表大小,则抛错 */
return DICT_ERR;
dictht n; /* 新 hash 表 */
unsigned long realsize = _dictNextPower(size); /* 重新计算扩容后的值,必须为 2 的 N 次方幂 */
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR; /* 重新计算的值如果和原来的 size 相等,则无效 */
/* 分配新 Hash 表,并初始化所有指针为 NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* 初始化的情况,而不是进行 rehash 操作,就用 ht[0] 来接收值 */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* 准备第二个 Hash 表,以便执行渐进式哈希操作 */
d->ht[1] = n; /* 扩容后的新内存放入 ht[1] 中 */
d->rehashidx = 0; /* 非默认的 -1,表示需进行 rehash */
return DICT_OK;
}
redis中的key可能有成千上万,如果一次性扩容,会对性能造成巨大的影响,所以redis使用渐进式扩容,每次执行插入,删除,查找,修改等操作前,都先判断当前字典的rehash操作是否在进行,如果是在进行中,就对当前节点进行rehash操作,只执行一次。除此之外,当服务器空闲时,也会调用incrementallyRehash函数进行批量操作,每次100个节点,大概一毫秒。将rehash操作进行分而治之。
渐进式rehash源码:
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* 最大访问的空桶的数量,n*10 */
if (!dictIsRehashing(d)) return 0; /* dict 没有正在进行 rehash 时,直接返回 */
while(n-- && d->ht[0].used != 0) { /* n 为最多迁移元素数量 */
dictEntry *de, *nextde;
assert(d->ht[0].size > (unsigned long)d->rehashidx); /* 为防止 rehashidx 越界,当 rehashidx 大于 ht[0] 的数组大小时,不继续执行 */
while(d->ht[0].table[d->rehashidx] == NULL) { /* 当 rehashidx 位置的桶为空时,继续向下遍历,直到桶不为空或者达到最大访问空桶的数量 */
d->rehashidx++;
if (--empty_visits == 0) return 1; //最大访问空桶数量-1,若减完,则退出
}
de = d->ht[0].table[d->rehashidx];
while(de) { // 遍历桶中元素,移动元素至新表
uint64_t h;
nextde = de->next;
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h]; // 头插法
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL; // ht[0] 对应桶置为空
d->rehashidx++;
}
if (d->ht[0].used == 0) { // 检查是否已经 rehash 完成
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
return 1;
}
查找元素
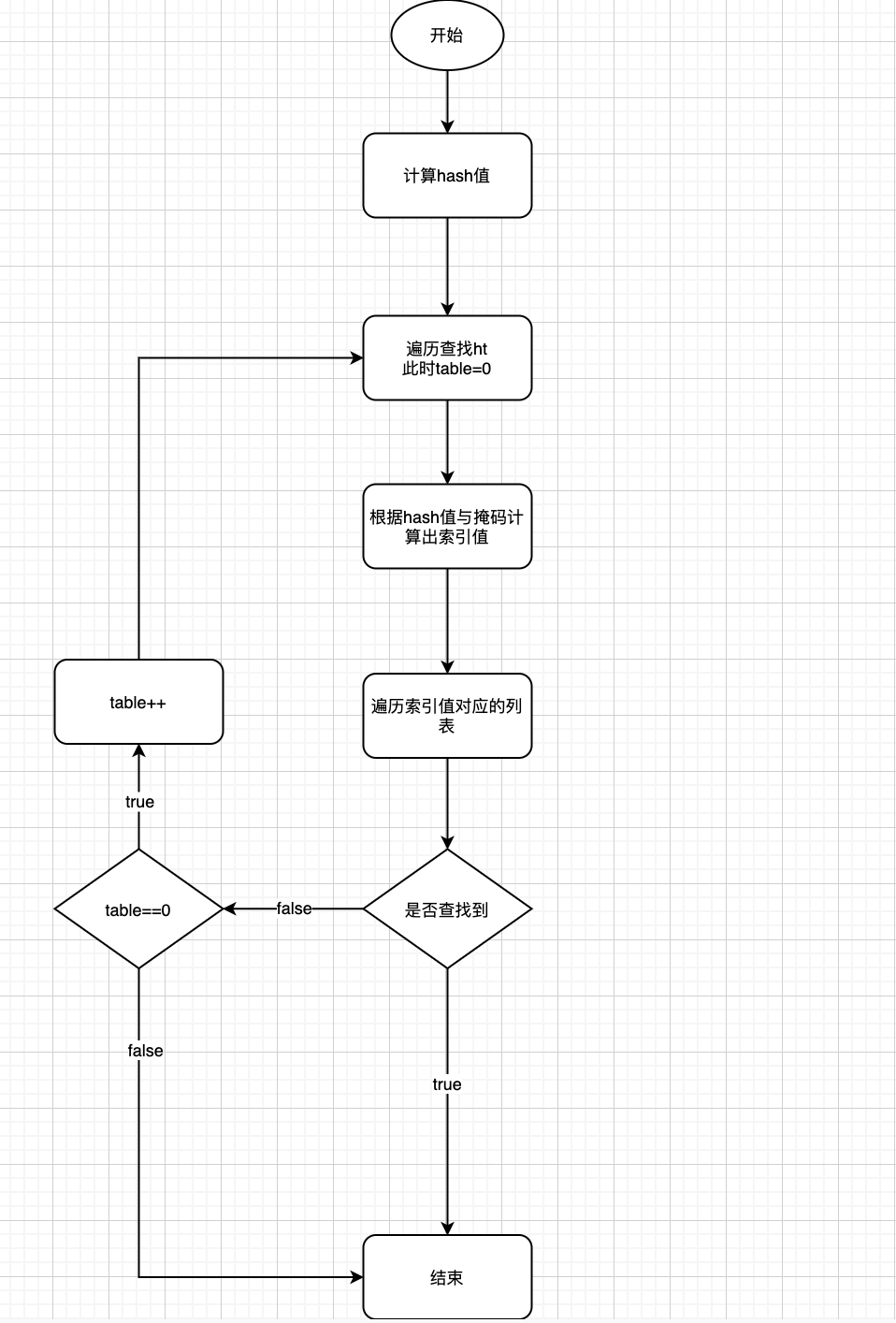
更新和删除操作大同小异,不在赘述。
应用场景
- 总长度超过512字节或者单个元素长度大于64的Hash
- 总长度超过512字节或者单个元素长度大于64的set
压缩列表
redis使用字节数据表示压缩列表,尽最大可能节省空间。
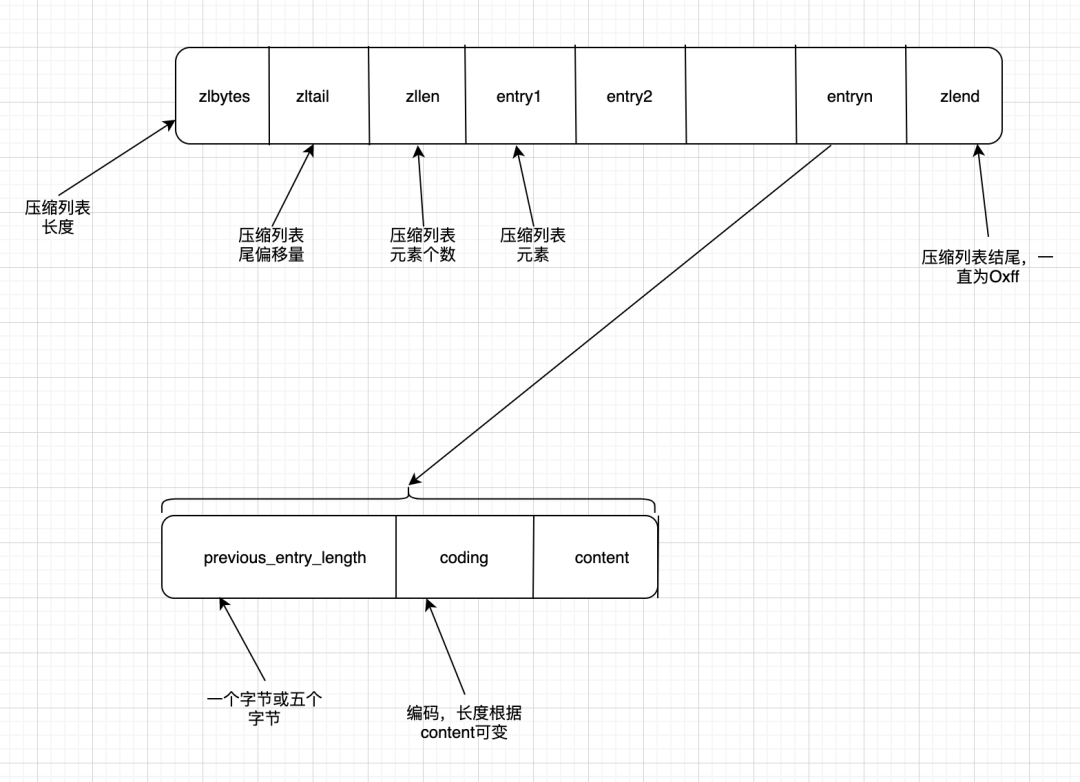
其中,coding字段表示content的编码,其长度是动态变化的。如下表:
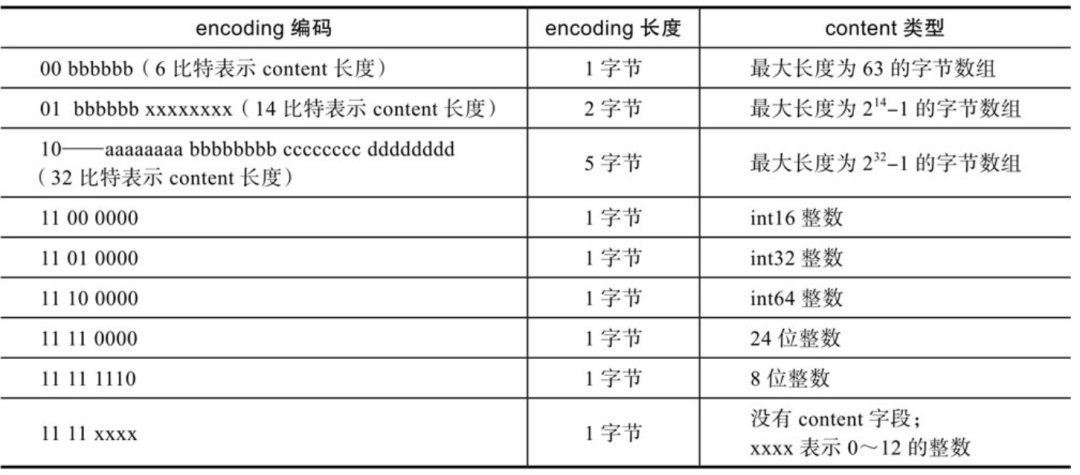
encoding字段第1个字节的前2位,可以判断content字段存储的是整数或者字节数组。当content存储的是字节数组时,后续字节标识字节数组的实际长度;当content存储的是整数时,可根据第3、第4位判断整数的具体类型。而当encoding字段标识当前元素存储的是0~12的立即数时,数据直接存储在encoding字段的最后4位,此时没有content字段。
举个例子:
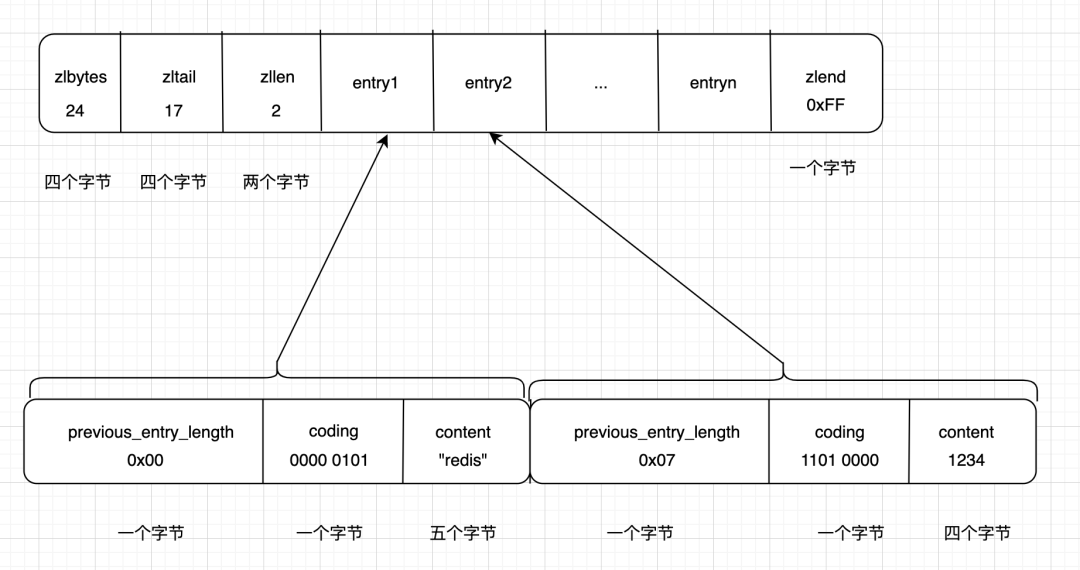
数据结构
因为解码过程比较繁琐,每次解码都需要性能损耗,为此定义了结构体zlentry,用于表示解码后的压缩列表元素:
typedef struct zlentry {
//previous_entry_length 长度
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
// previous_entry_length
unsigned int prevrawlen; /* Previous entry len. */
//encoding 长度
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
// 内容的长度
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
//首部长度
unsigned int headersize; /* prevrawlensize + lensize. */
//编码
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
// 当前元素的首地址
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
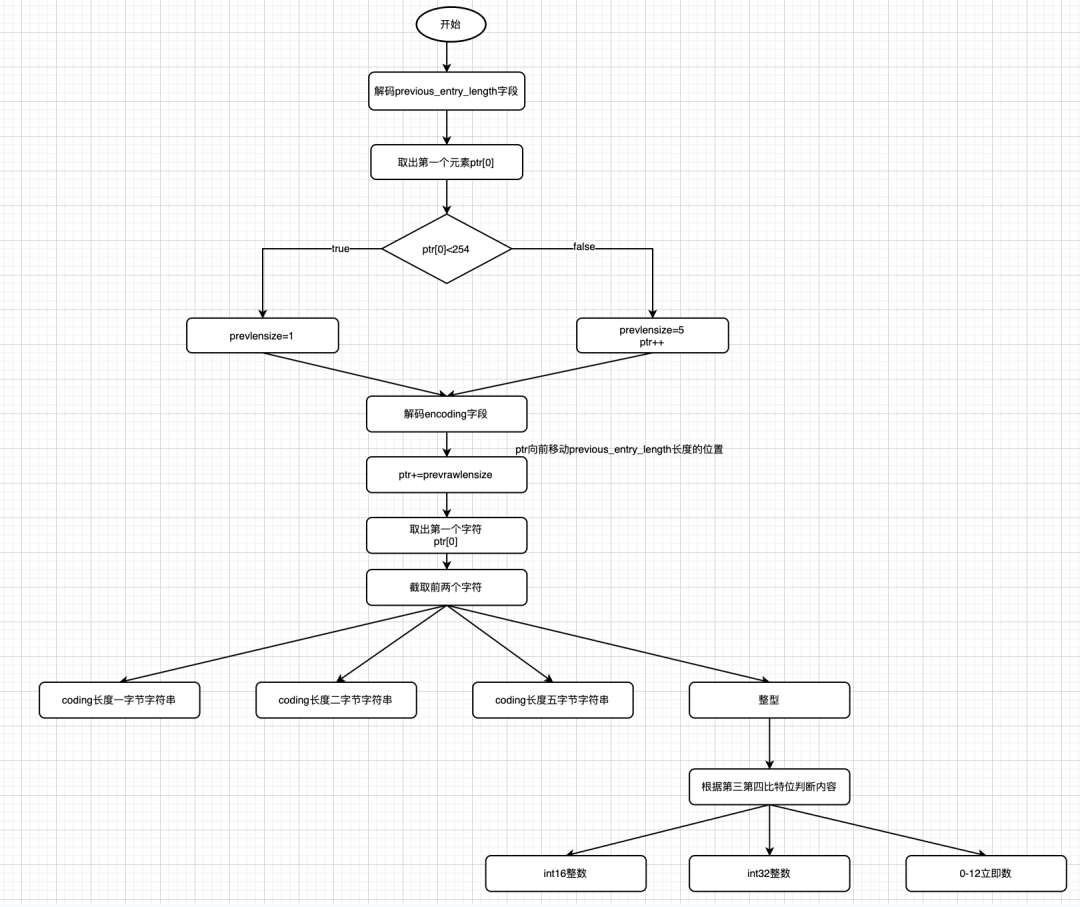
解码
解码分为两步,解码previousentrylength和解码coding
- 解码previousentrylength
#define ZIP_DECODE_PREVLEN(ptr, prevlensize, prevlen) do {
ZIP_DECODE_PREVLENSIZE(ptr, prevlensize);
// prevlensize=1时,则 ptr 的第一个字节标识上一个节点的长度
if ((prevlensize) == 1) {
(prevlen) = (ptr)[0];
} else if ((prevlensize) == 5) {
assert(sizeof((prevlen)) == 4);
// 如果 prevlensize = 5,取后面 4 个字节作为上一节点的长度
memcpy(&(prevlen), ((char*)(ptr)) + 1, 4);
memrev32ifbe(&prevlen);
}
} while(0);
- 解码coding
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do {
// 获取当前的编码类型
ZIP_ENTRY_ENCODING((ptr), (encoding));
// 如果编码类型为字节数组
if ((encoding) < ZIP_STR_MASK) {
// encoding == 00000000
if ((encoding) == ZIP_STR_06B) {
// 存储元素的长度数值所需要的字节数设置为 1
(lensize) = 1;
// 元素长度为 (ptr)[0] 和 111111 做位运算
(len) = (ptr)[0] & 0x3f;
// encoding == 10000000
} else if ((encoding) == ZIP_STR_14B) {
// 存储元素的长度数值所需要的字节数设置为 2
(lensize) = 2;
// 元素长度为 高八位:(ptr)[0] 和 111111 做位运算 低八位:(ptr)[1]
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1];
// encoding == 11000000
} else if ((encoding) == ZIP_STR_32B) {
// 存储元素的长度数值所需要的字节数设置为 5
(lensize) = 5;
// 元素长度为后 4 位
(len) = ((ptr)[1] << 24) |
(ptr)[2] << 16) |
(ptr)[3] << 8) |
((ptr)[4]);
} else {
panic("Invalid string encoding 0x%02X", (encoding));
}
} else {
// 数值类型长度存储为 1 字节
(lensize) = 1;
// 元素长度
(len) = zipIntSize(encoding);
}
} while(0);
编码
static unsigned int zipPrevEncodeLength(unsigned char *p, unsigned int len) {
// 仅返回编码 len 所需的字节数量
if (p == NULL) {
return (len < ZIP_BIGLEN) ? 1 : sizeof(len)+1;
// 写入并返回编码 len 所需的字节数量
} else {
// 1 字节
if (len < ZIP_BIGLEN) {
p[0] = len;
return 1;
// 5 字节
} else {
// 添加 5 字节长度标识
p[0] = ZIP_BIGLEN;
// 写入编码
memcpy(p+1,&len,sizeof(len));
// 如果有必要的话,进行大小端转换
memrev32ifbe(p+1);
// 返回编码长度
return 1+sizeof(len);
}
}
}
连锁更新
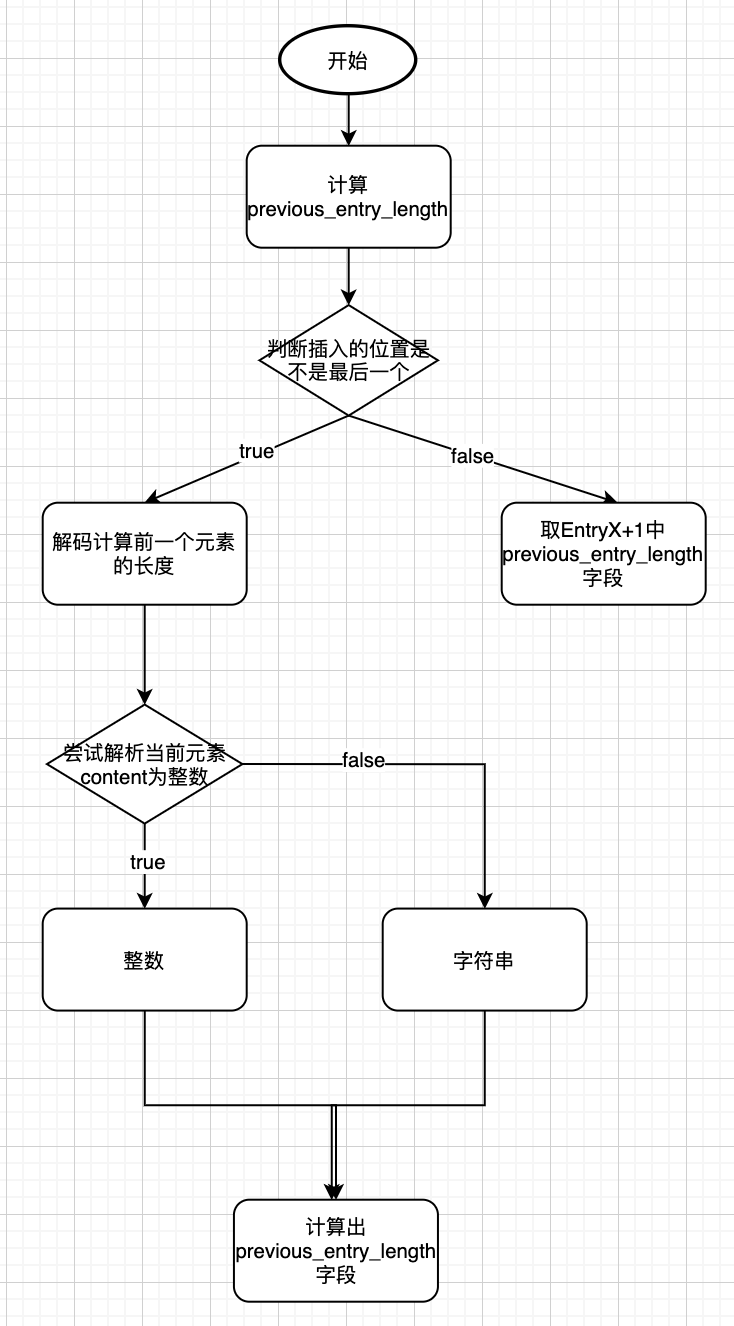
重新回顾一下 如果前驱节点的长度小于254,那么preventrylen成员需要用1字节长度来保存这
个长度值。如果前驱节点的长度大于等于254,那么preventrylen成员需要用5字节长度来保存这个长度值。举个例子:
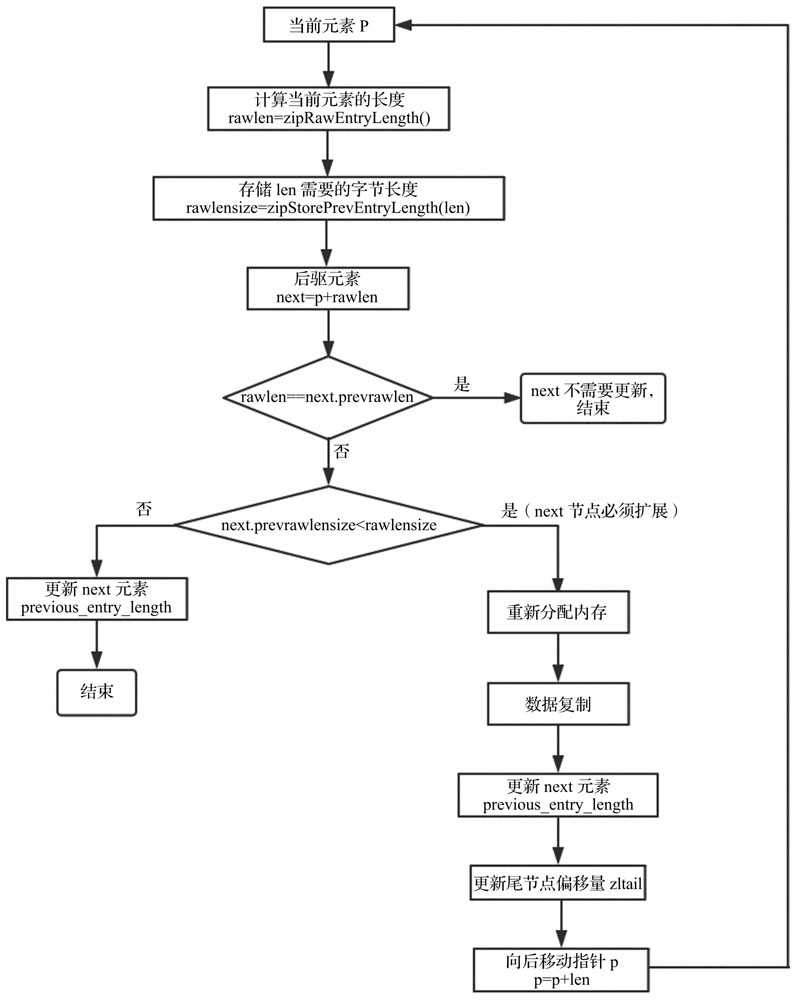
比如有这么连续的四个节点,大小都是253字节,当最前面加入一个大于254字节的节点,会导致后面的节点因为因为previousentrylength从一个字节变成五个字节而频繁扩容,每次扩容缩容都需要分配空间和复制数据,对性能损耗巨大。
因为连锁更新发生的概率十分十分低,所以redis并没有采取相关的措施去避免 最后附一张连锁更新的流程图。
应用场景
- 所有字符串元素的长度都小于 64 字节并且保存的元素数量小于512个的列表(list)
- 所有字符串元素的长度都小于 64 字节并且保存的元素数量小于512个的哈希表(Hash)
- 所有字符串元素的长度都小于 64 字节并且保存的元素数量小于512个的有序集合(Sorted Set)
Stream流
Stream流结构
redis中Stream流是Redis5.0以后新加入的数据结构,由生产者,消息,消费者,消费组四个部分组成。
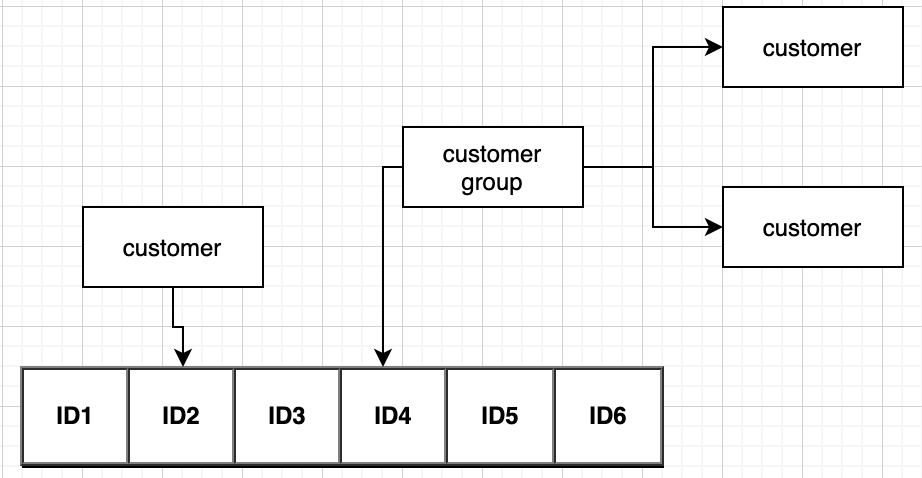
生产者负责向消息队列中生产消息,消费者消费某个消息流 对于消费组,有以下三点:
- 每个消费组可以消费消息队列中的所有消息,且消费组之间独立
- 每个消费组里有多个消费者,消息队列中的一条消息只能被其中的一个消费者消费
- 消费组和消费者都维护了已消费待确认的队列
listpack结构
listpack可以理解为一个字符串序列化队列,可以存储字符串或者整型c语言中没有定义listpack的结构体,因为listpack本身可以理解为是一个字符串数组。

其中encode编码字段,决定了后面的content的内容形式,具体如下表所示:

backlen所占用的每个字节的第一个bit用于标识;0代表结束,1代表尚未结束,每个字节只有7 bit有效,用于从后向前遍历,能够快速找到上一个元素的首字符。
listpack基本操作
该结构查找效率低下,所以只适合在结尾增删,这刚好符合消息队列的操作。
增删改节点
listpack中增删改操作都是用的同一个方法lpInsert,实现了在任意位置插入元素。删除操作转换为用空元素替换操作,代码比较多,主要介绍一下流程:

插入元素的流程也比较简单,就和在数组中插入一个元素类似,不做过多的介绍。
遍历
类似数组的遍历,从前向后遍历。
RAX结构
我们经常会用到前缀树来查找一个单词,查找时间复杂度是O(len(单词的长度))。
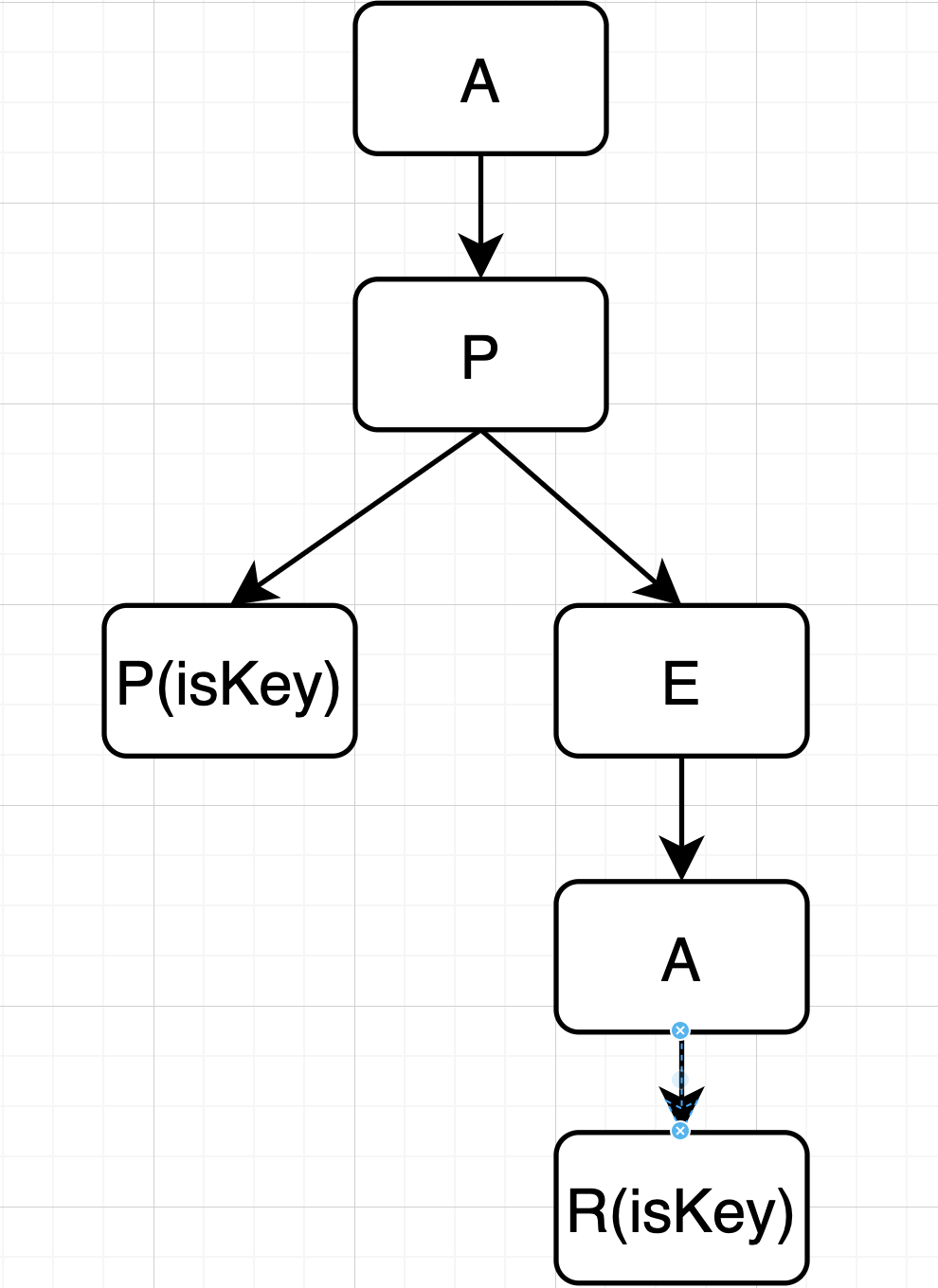
比如上图这样一棵前缀树,包含了两个单词,App,Apear。
这是一种典型的空间换时间的方式,但是每个节点存储一个字母,是不是有点浪费了呢,Rax的出现就解决了这个问题。
下图为使用Rax结构保存App和Apear结构:
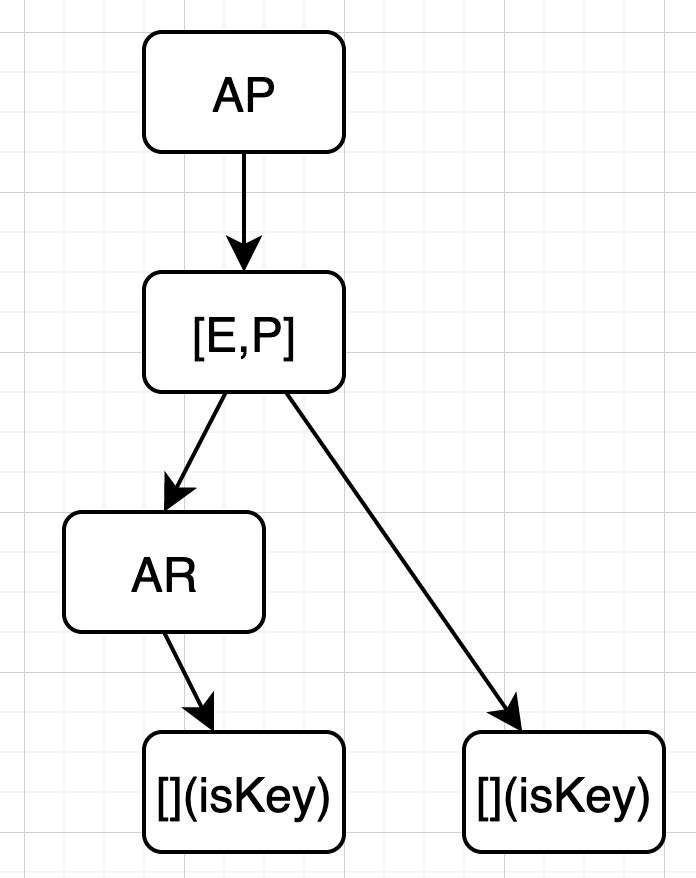
其中使用带中括号表示的是非压缩节点,其它节点为压缩节点。另外,非压缩节点是按照字典序排序的。
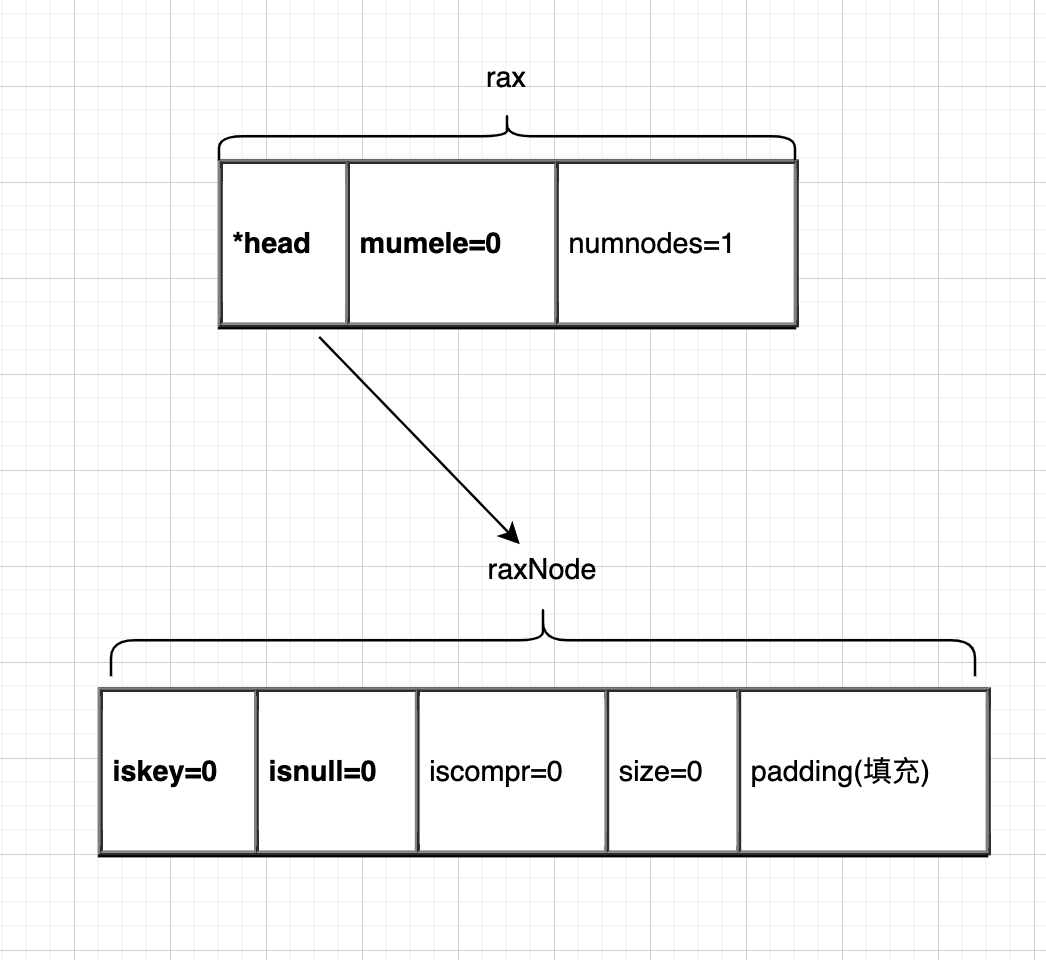
数据结构
typedef struct rax {
// 头结点
raxNode *head;
// 元素数量(key的数量)
uint64_t numele;
// 节点数量
uint64_t numnodes;
} rax;
typedef struct raxNode {
// 当前节点是否包含key
uint32_t iskey:1; /* Does this node contain a key? */
// 当前key对应的value是否为null
uint32_t isnull:1; /* Associated value is NULL (don't store it). */
// 是否压缩
uint32_t iscompr:1; /* Node is compressed. */
// 压缩节点长度或者非压缩节点个数
uint32_t size:29;
unsigned char data[];
}
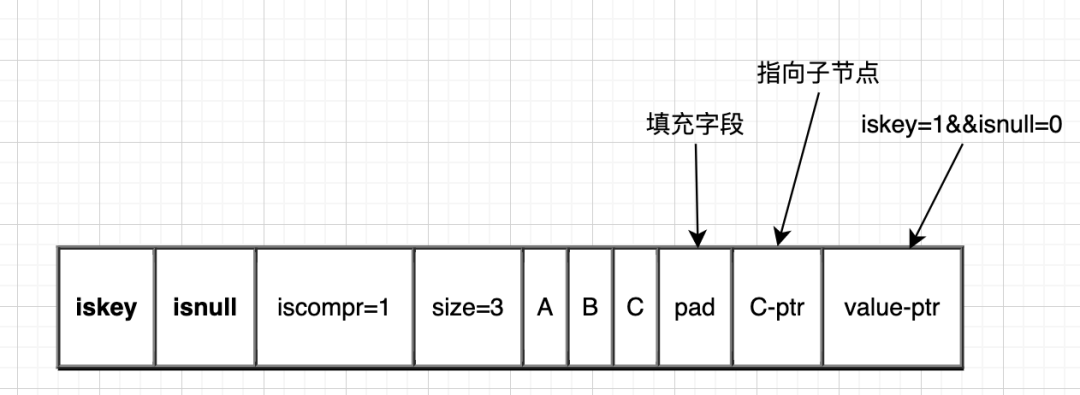
压缩节点:
非压缩节点:
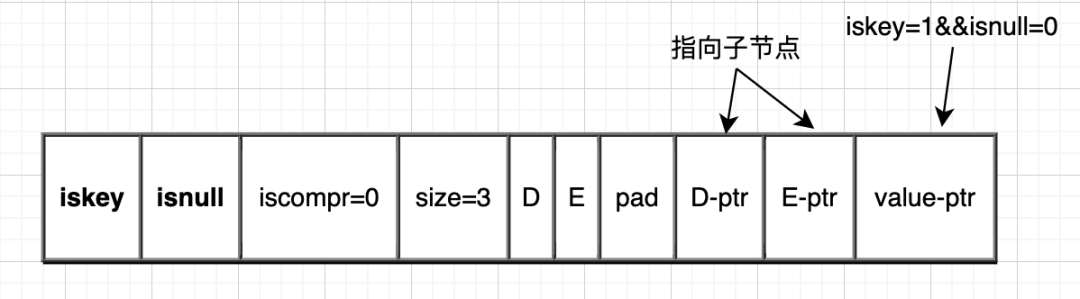
压缩节点与非压缩节点最大的不同,除了iscomper标志字段不同外,压缩节点只有最后一个字符有子节点,而非压缩节点每个字符都有子节点。
Stream底层实现
如果Stream底层将消息都存放在listpack中,会存在性能问题。当查询消息的时候,需要遍历listpack,插入消息的时候,需要重新分配一块很大的空间。
rax *raxNew(void) {
rax *rax = rax_malloc(sizeof(*rax));
if (rax == NULL) return NULL;
rax->numele = 0;
rax->numnodes = 1;
rax->head = raxNewNode(0,0);
if (rax->head == NULL) {
rax_free(rax);
return NULL;
} else {
return rax;
}
}
查找元素
/**
* 根据key获取对应的value
* @param rax 待查找的rax
* @param s 待查找的key
* @param len s的长度
* @return
*/
void *raxFind(rax *rax, unsigned char *s, size_t len) {
raxNode *h;
debugf("### Lookup: %.*s\n", (int)len, s);
int splitpos = 0;
size_t i = raxLowWalk(rax,s,len,&h,NULL,&splitpos,NULL);
if (i != len || (h->iscompr && splitpos != 0) || !h->iskey)
return raxNotFound;
return raxGetData(h); //返回对应的value
}
可以看到,主要的代码在raxLowWalk方法中。
/**
*
* @param rax 待查找的rax
* @param s 待查找的key
* @param len s的长度
* @param stopnode 终止的节点 要么匹配完成,要么没找到。。
* @param plink 父节点指向stopnode的指针的地址
* @param splitpos 压缩节点的匹配位置
* @param ts 记录路径
* @return
*/
static inline size_t raxLowWalk(rax *rax, unsigned char *s, size_t len, raxNode **stopnode, raxNode ***plink, int *splitpos, raxStack *ts) {
// 从根节点开始查找
raxNode *h = rax->head;
raxNode **parentlink = &rax->head;
// 当前匹配字符位置
size_t i = 0; /* Position in the string. */
// 当前匹配节点位置
size_t j = 0; /* Position in the node children (or bytes if compressed).*/
// 当前节点有子节点且s字符串没有遍历完
while(h->size && i < len) {
debugnode("Lookup current node",h);
unsigned char *v = h->data;
if (h->iscompr) {
//压缩节点判断是否完全匹配
for (j = 0; j < h->size && i < len; j++, i++) {
if (v[j] != s[i]) break;
}
// 没有遍历完字符串,退出
if (j != h->size) break;
} else {
/* Even when h->size is large, linear scan provides good
* performances compared to other approaches that are in theory
* more sounding, like performing a binary search. */
// 非压缩节点
for (j = 0; j < h->size; j++) {
if (v[j] == s[i]) break;
}
// 未在非压缩节点找到字符串
if (j == h->size) break;
// 压缩节点可以匹配
i++;
}
// 记录路径
if (ts) raxStackPush(ts,h); /* Save stack of parent nodes. */
raxNode **children = raxNodeFirstChildPtr(h);
if (h->iscompr) j = 0; /* Compressed node only child is at index 0. */
// 移动到第j个子节点
memcpy(&h,children+j,sizeof(h));
parentlink = children+j;
j = 0; /* If the new node is compressed and we do not
iterate again (since i == l) set the split
position to 0 to signal this node represents
the searched key. */
}
debugnode("Lookup stop node is",h);
if (stopnode) *stopnode = h;
if (plink) *plink = parentlink;
if (splitpos && h->iscompr) *splitpos = j;
return i;
}
这里的步骤比较简单:
- 初始化变量
- 从根节点查找直到当前节点无子节点或者s字符串遍历完毕 如果是压缩节点,节点中字符需要和s中的字符完全匹配 如果是非压缩节点,需要找到至少一个与S中字符匹配的字符
- 如果匹配成功,就查找子节点。
添加元素
向rax中添加key-value对有两种方式,覆盖和不覆盖原有key对应的方法分别为:
int raxInsert(rax *rax, unsigned char *s, size_t len, void *data, void **old) {
return raxGenericInsert(rax,s,len,data,old,1);
}
int raxTryInsert(rax *rax, unsigned char *s, size_t len, void *data, void **old) {
return raxGenericInsert(rax,s,len,data,old,0);
}
两者都是调用同一个方法raxGenericInsert。该接口方法主要分为以下几步:
- 查找key是否存在
i = raxLowWalk(rax,s,len,&h,&parentlink,&j,NULL);
- key存在的情况下,直接更新节点数据
// 如果之前节点没有数据,就分配一个空间
if (!h->iskey || (h->isnull && overwrite)) {
h = raxReallocForData(h,data);
if (h) memcpy(parentlink,&h,sizeof(h));
}
if (h == NULL) {
errno = ENOMEM;
return 0;
}
/* Update the existing key if there is already one. */
// 更新数据
if (h->iskey) {
if (old) *old = raxGetData(h);
if (overwrite) raxSetData(h,data);
errno = 0;
return 0; /* Element already exists. */
}
key不存在的情况下,最后停留在某个压缩节点上;key不存在时,就分为多种情况,这里借用redis源码注解的例子。原来有个rax树,长这样:
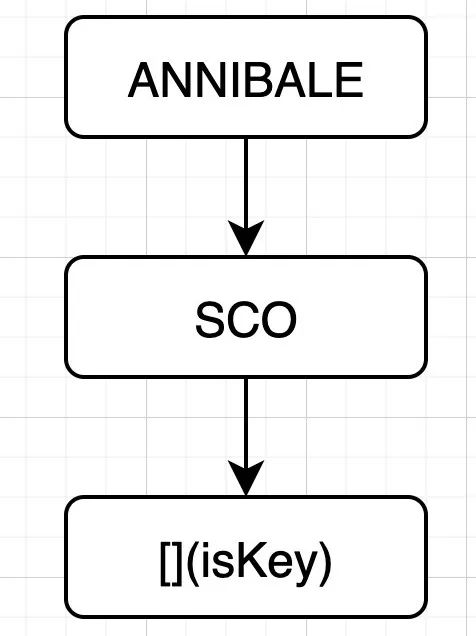
有以下几种插入情况:
- 插入 ANNIENTARE
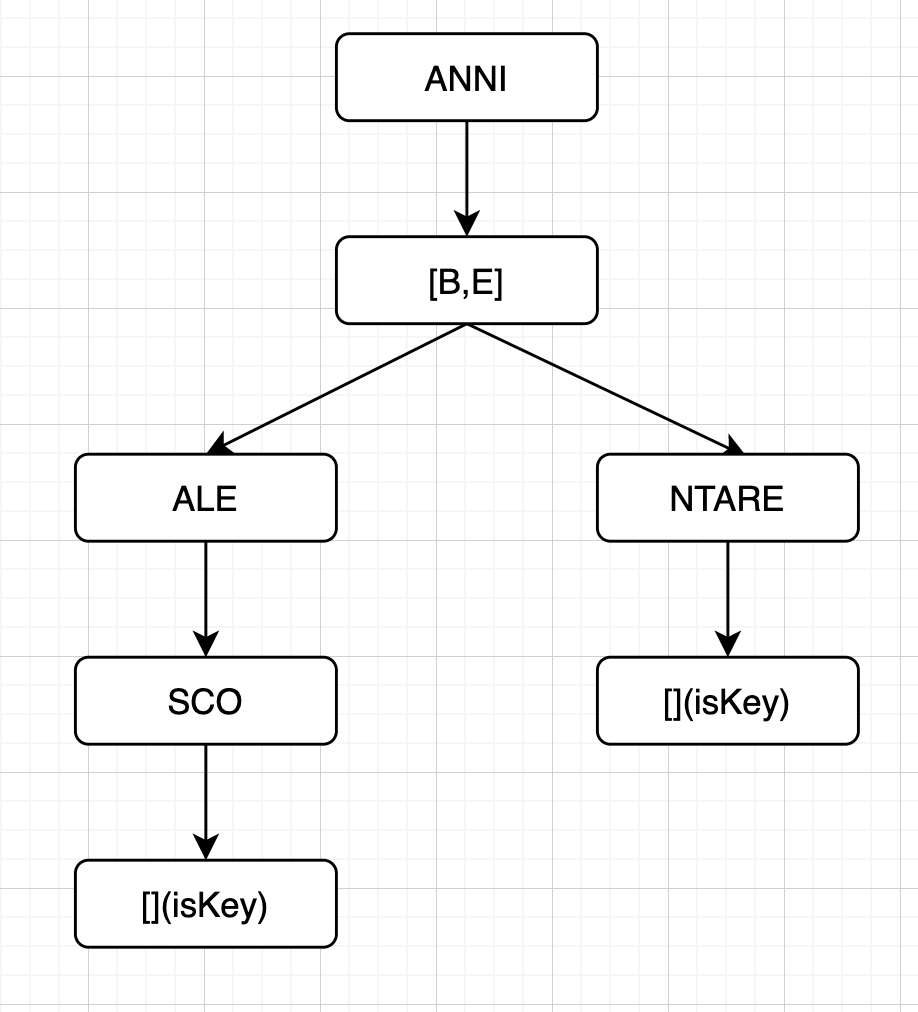
- 插入ANNIBALI
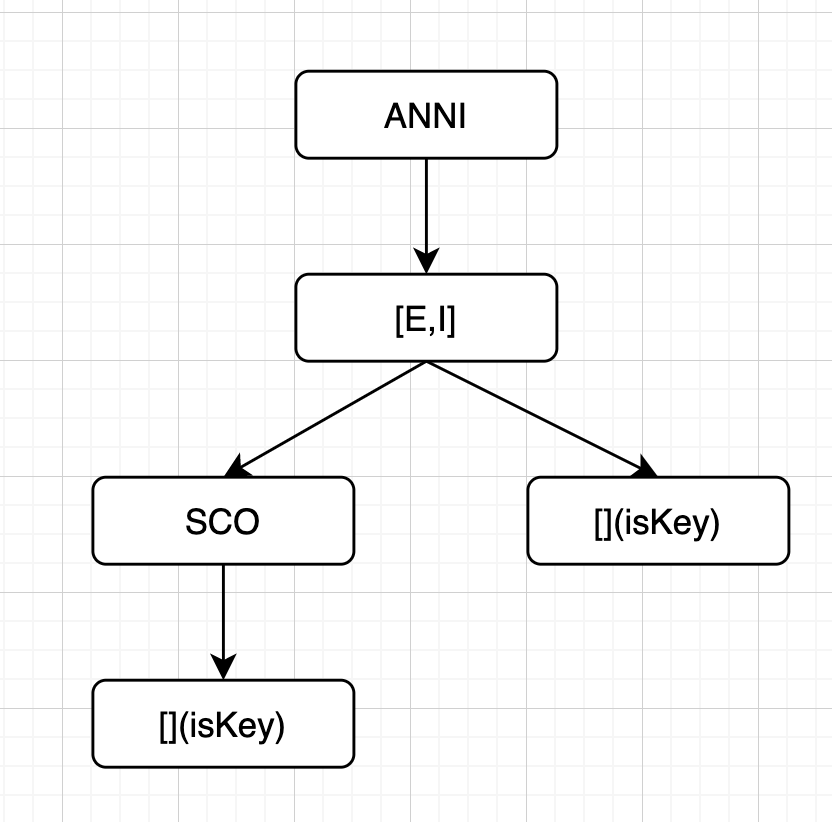
- 插入 AGO
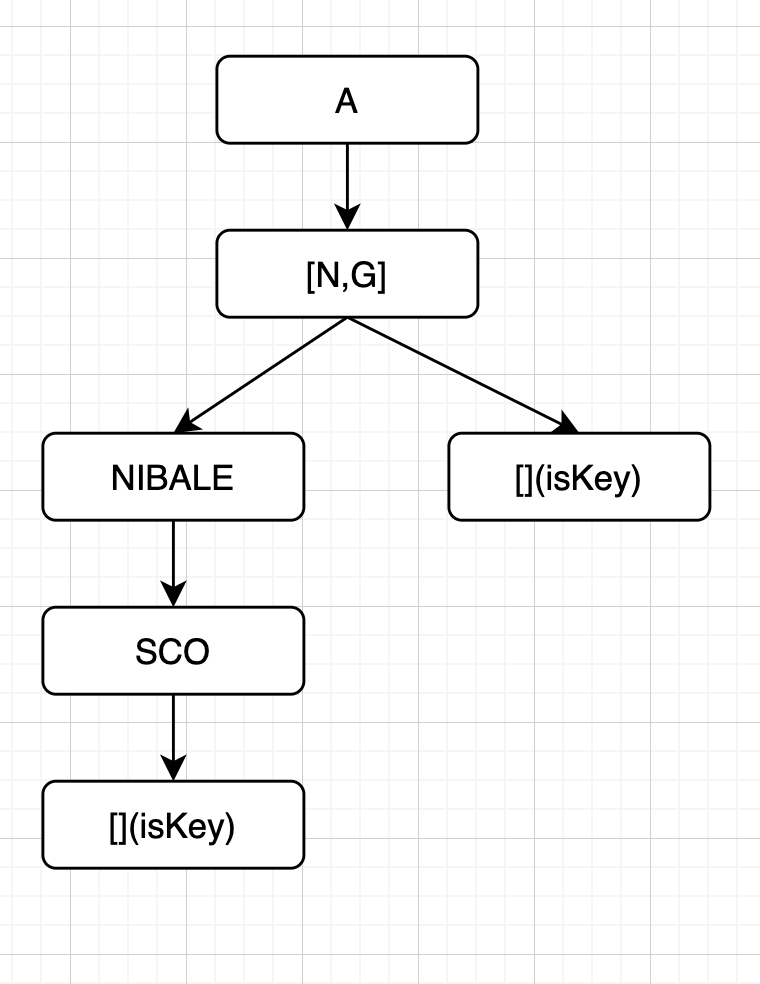
和第一种类似,只是右边的节点变成了非压缩节点。
- 插入 CIAO
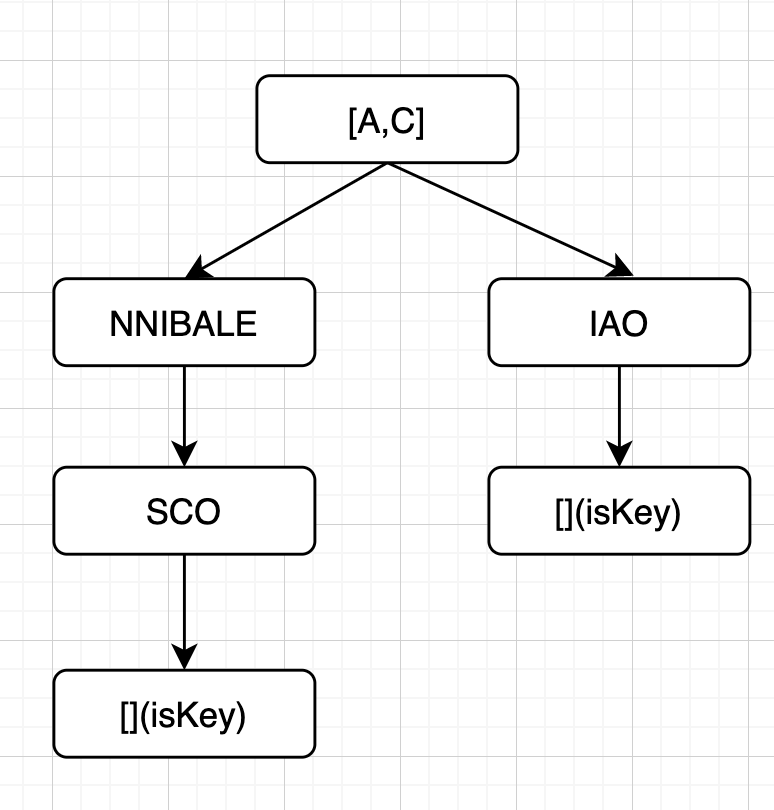
- 插入 ANNI
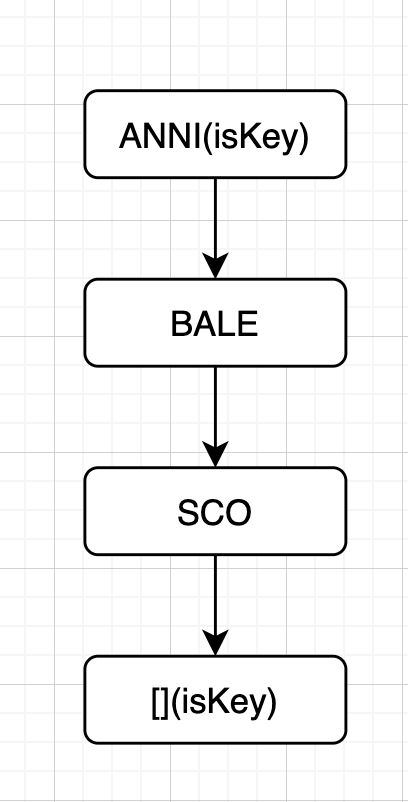
上面列举了五种情况,可以分为两类:
- 第一种是新插入的key是当前节点的一部分,这时我们只需要拆分压缩节点,并设置新的key即可
- 第二种是新插入的key与压缩节点的某个位置不匹配,这时我们需要在拆分后的相应位置的非压缩节点中,插入新key的不匹配字符,之后将新key的剩余部分,插入到这个非压缩节点的子节点中
源码中细节较多,不再细讲 感兴趣的同学可以查看。
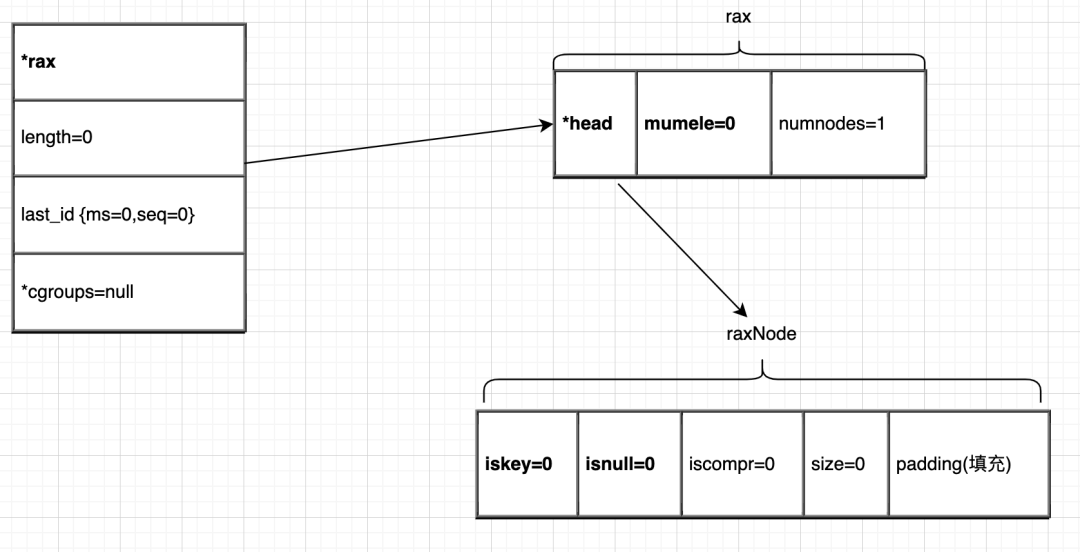
stream结构
stream流就像是一个消息链表,依赖于Rax结构和listpack结构,本节主要介绍消息流的增删查操作。
typedef struct stream {
// 指向rax树
rax *rax;
// 元素个数
uint64_t length;
// 指向最后一个消息
streamID last_id;
// 消费组
rax *cgroups;
} stream;
结构如下图所示:
基本操作
添加消息
redis提供streamAppendItem 函数,向stream中添加一个新的消息。
/**
*
* @param s 待插入的数据流
* @param argv 消息内容
* @param numfields 消息数量
* @param added_id 消息id
* @param use_id 调用方定义的id
* @return
*/
int streamAppendItem(stream *s, robj **argv, int64_t numfields, streamID *added_id, streamID *use_id)
代码比较多就不贴了,画一张流程图描述细节。
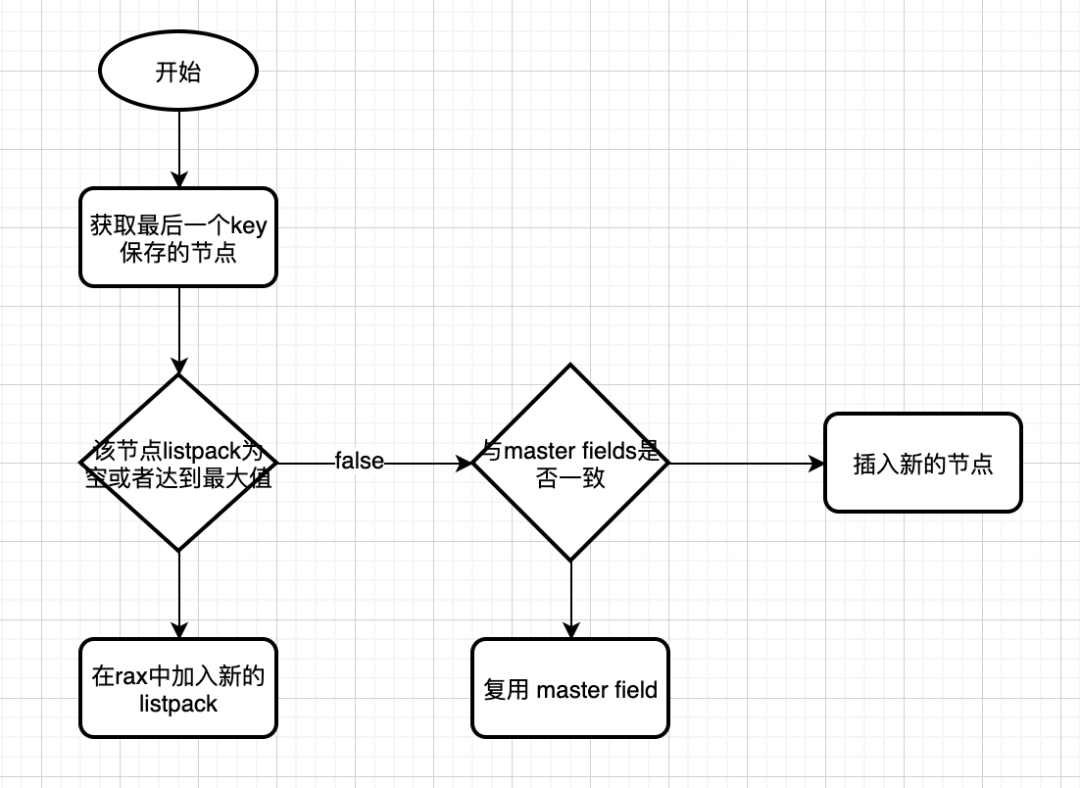
新增消费组
消费组也是保存在rax树中,以消费组的名称为key,消费组的streamCG结构为value。
treamCG *streamCreateCG(stream *s, char *name, size_t namelen, streamID *id) {
//当前消息流没有消费组,就新建一个
if (s->cgroups == NULL) s->cgroups = raxNew();
// 查找是否有重名消费组,有就直接返回
if (raxFind(s->cgroups,(unsigned char*)name,namelen) != raxNotFound)
return NULL;
// 新建消费组
streamCG *cg = zmalloc(sizeof(*cg));
cg->pel = raxNew();
cg->consumers = raxNew();
cg->last_id = *id;
// 将消费组插入到消费组树中
raxInsert(s->cgroups,(unsigned char*)name,namelen,cg,NULL);
return cg;
}
新建消费者
redis没有提供为消费组中新增消费者的方法。在查询消费者的时候,如果不存在,就会新增。
删除消息
删除消息通过将listpack中消息的标志位设为已删除,并不是真正的删除。如果整个listpack的消息都被删除了,才会从rax中释放该节点。
void streamIteratorRemoveEntry(streamIterator *si, streamID *current) {
// 当前消息所在的listpack
unsigned char *lp = si->lp;
int64_t aux;
// 标记删除位
int flags = lpGetInteger(si->lp_flags);
flags |= STREAM_ITEM_FLAG_DELETED;
lp = lpReplaceInteger(lp,&si->lp_flags,flags);
//修改有效的消息数量
unsigned char *p = lpFirst(lp);
aux = lpGetInteger(p);
// 如果只有待删除的消息,就直接释放listpack
if (aux == 1) {
/* If this is the last element in the listpack, we can remove the whole
* node. */
lpFree(lp);
raxRemove(si->stream->rax,si->ri.key,si->ri.key_len,NULL);
} else {
// 更新统计信息
lp = lpReplaceInteger(lp,&p,aux-1);
// 查找删除节点p
p = lpNext(lp,p);
aux = lpGetInteger(p);
lp = lpReplaceInteger(lp,&p,aux+1);
// 更新listpack指针,可能因为扩容缩容而变化
if (si->lp != lp)
raxInsert(si->stream->rax,si->ri.key,si->ri.key_len,lp,NULL);
}
查找消费组
主要是利用rax查询接口:
streamCG *streamLookupCG(stream *s, sds groupname) {
if (s->cgroups == NULL) return NULL;
streamCG *cg = raxFind(s->cgroups,(unsigned char*)groupname,
sdslen(groupname));
return (cg == raxNotFound) ? NULL : cg;
}
查找消费者
streamConsumer *streamLookupConsumer(streamCG *cg, sds name, int create) {
// 在消费者的rax中查找指定的消费者
streamConsumer *consumer = raxFind(cg->consumers,(unsigned char*)name,
sdslen(name));
if (consumer == raxNotFound) {
if (!create) return NULL;
// 如果没有找到,新建一个消费者,插入到消费者rax树中
consumer = zmalloc(sizeof(*consumer));
consumer->name = sdsdup(name);
consumer->pel = raxNew();
raxInsert(cg->consumers,(unsigned char*)name,sdslen(name),
consumer,NULL);
}
consumer->seen_time = mstime();
return consumer;
}
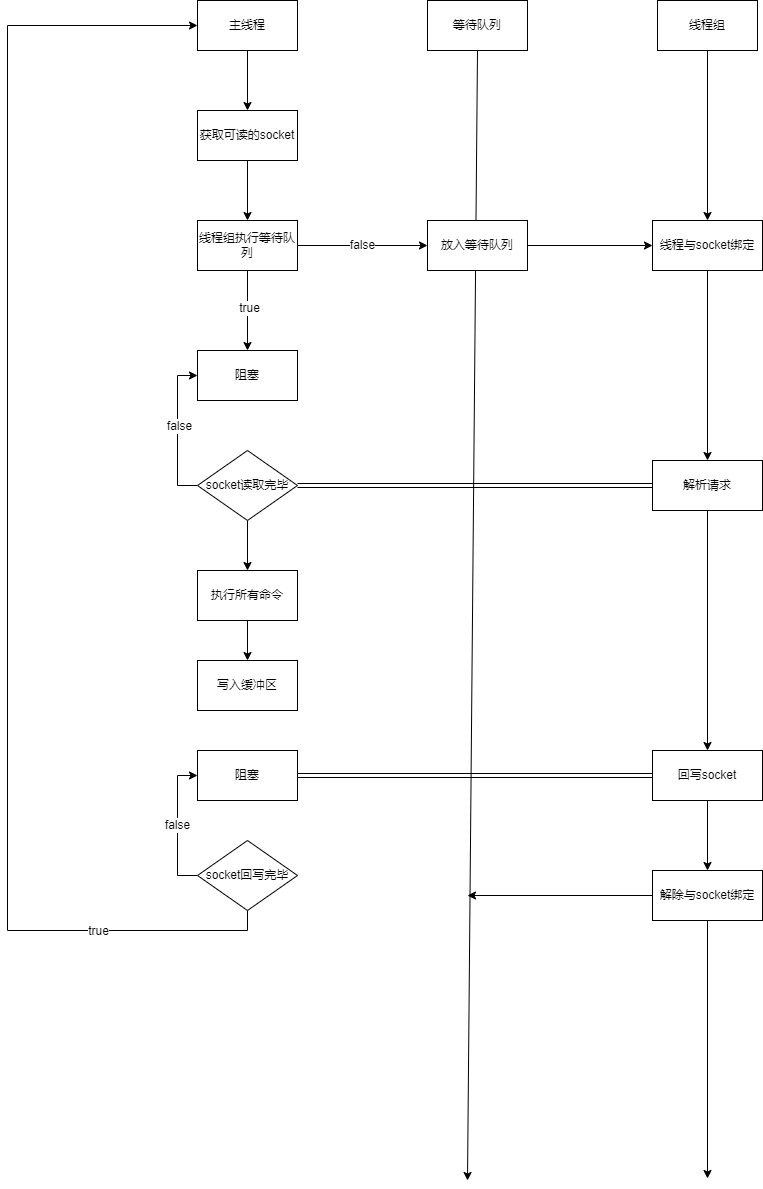
Redis线程模型演进
Redis3.0
redis内部使用文件事件处理器file event handler,这个文件处理器是单线程的,所以我们经常说的redis是单线程模型。
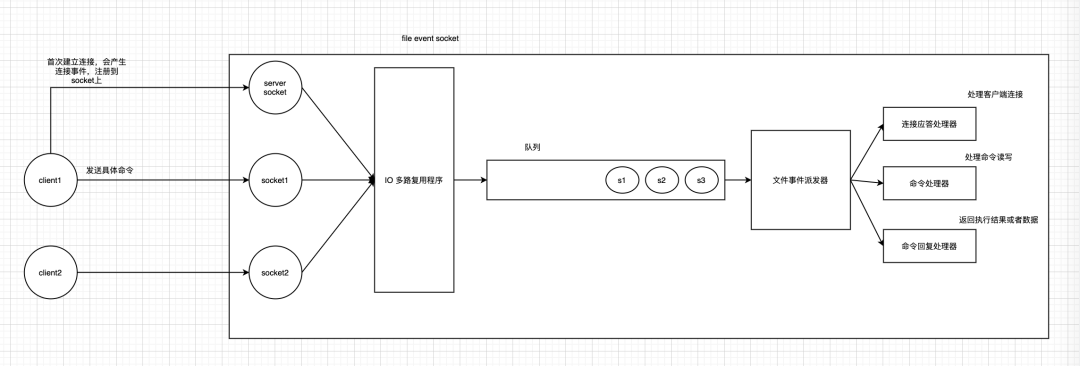
客户端 Socket01 向 Redis 的 Server Socket 请求建立连接,此时 Server Socket 会产生一个 AEREADABLE 事件,IO 多路复用程序监听到 server socket 产生的事件后,将该事件压入队列中。文件事件分派器从队列中获取该事件,交给连接应答处理器。连接应答处理器会创建一个能与客户端通信的 Socket01,并将该 Socket01 的 AEREADABLE 事件与命令请求处理器关联。
假设此时客户端发送了一个 set key value 请求,此时 Redis 中的 Socket01 会产生 AEREADABLE 事件,IO 多路复用程序将事件压入队列,此时事件分派器从队列中获取到该事件,由于前面 Socket01 的 AEREADABLE 事件已经与命令请求处理器关联,因此事件分派器将事件交给命令请求处理器来处理。命令请求处理器读取 Scket01 的 set key value 并在自己内存中完成 set key value 的设置。操作完成后,它会将 Scket01 的 AE_WRITABLE 事件与令回复处理器关联。
如果此时客户端准备好接收返回结果了,那么 Redis 中的 Socket01 会产生一个 AEWRITABLE 事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复处理器对 socket01 输入本次操作的一个结果,比如 ok,之后解除 Socket01 的 AEWRITABLE 事件与命令回复处理器的关联。
Redis4.0
redis4.0开始引入了多线程,除了主线程,redis有后台线程进行一些边缘的缓慢的操作,比如释放无用连接,rehash迁移等操作。
Redis6.0
在redis6.0中,真正引入了多线程。