Redis 常见数据类型和应用场景
转载:一灯架构
参考:小林coding
我们都知道 Redis 提供了丰富的数据类型,常见的有五种:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
随着 Redis 版本的更新,后面又支持了四种数据类型: BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增)。
String(字符串)
String(字符串)是Redis中最基本的数据结构之一,它可以存储任意类型的数据,包括数字、文本、序列化的对象等。Redis中的字符串最大可以存储512MB的数据。
使用方式
字符串类型的操作是最基本的,包括设置值、获取值、修改值、追加值等。字符串类型支持的操作包括:

应用场景
- 缓存:将计算结果、数据库查询结果或者配置数据存储在Redis中,可以提高应用的响应速度和吞吐量。
- 计数器:使用Redis的自增和自减操作,实现简单的计数器功能,如网站的访问次数统计
- 限流:使用Redis的incr和expire命令,实现固定窗口算法的流量控制,防止系统过载。
- 分布式锁:使用SETNX操作实现分布式锁,保证同一时刻只有一个线程访问临界资源。
- 会话管理:将用户会话信息存储在Redis中,可以实现分布式Session。
内部编码
Redis字符串的内部编码有三种:
- int编码:当字符串长度小于等于12字节并且字符串可以表示为整数时,Redis会使用int编码。这样可以节省内存,并且在执行一些命令时可以直接进行数值计算。
- embstr编码:当字符串长度小于等于39字节时,Redis会使用embstr编码。这种编码方式会将字符串和存储它的结构体一起分配在内存中,这样可以减少内存碎片和结构体的开销。
- raw编码:当字符串长度大于39字节或者字符串不能表示为整数时,Redis会使用raw编码。这种编码方式直接将字符串存储在一个结构体中,没有进行任何优化。
Hash(哈希)
使用方式
哈希类型是一种键值对的集合,其中键值对的值可以是字符串、列表或者其他哈希类型。哈希类型支持的操作包括:
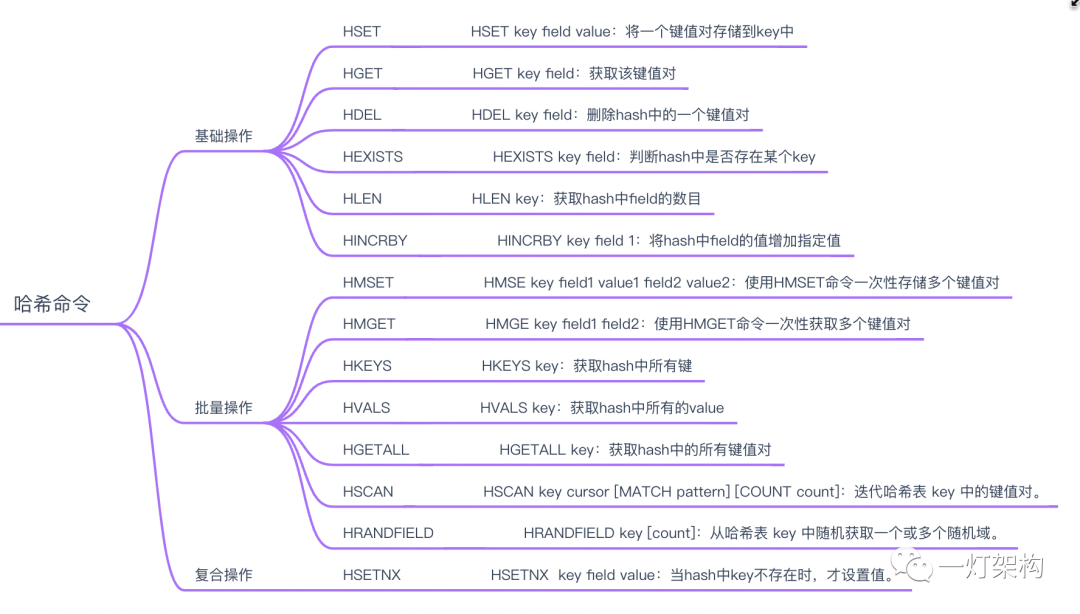
应用场景
- 存储对象:将对象的属性和属性值存储在哈希类型中,可以很方便地进行查询和更新操作,比如常见的用户信息就适合使用哈希类型存储。
内部编码
Redis哈希类型的内部编码有两种:
- ziplist(压缩列表):当Hash类型的元素比较少,且元素的大小比较小(小于64字节)时,Redis采用ziplist作为Hash类型的内部编码。ziplist是一种紧凑的、压缩的列表结构,可以节省内存空间。但是,ziplist只能进行线性查找,不支持快速的随机访问。
- hashtable(字典):当Hash类型的元素比较多,或者元素的大小比较大(大于64字节)时,Redis采用hashtable作为Hash类型的内部编码。hashtable是一种基于链表的哈希表结构,可以快速地进行随机访问。但是,hashtable需要占用更多的内存空间。
List(列表)
使用方式
Redis List类型是一个有序的字符串列表,支持在列表的头部或尾部添加元素,也支持在列表任意位置插入或删除元素。支持的操作包括:
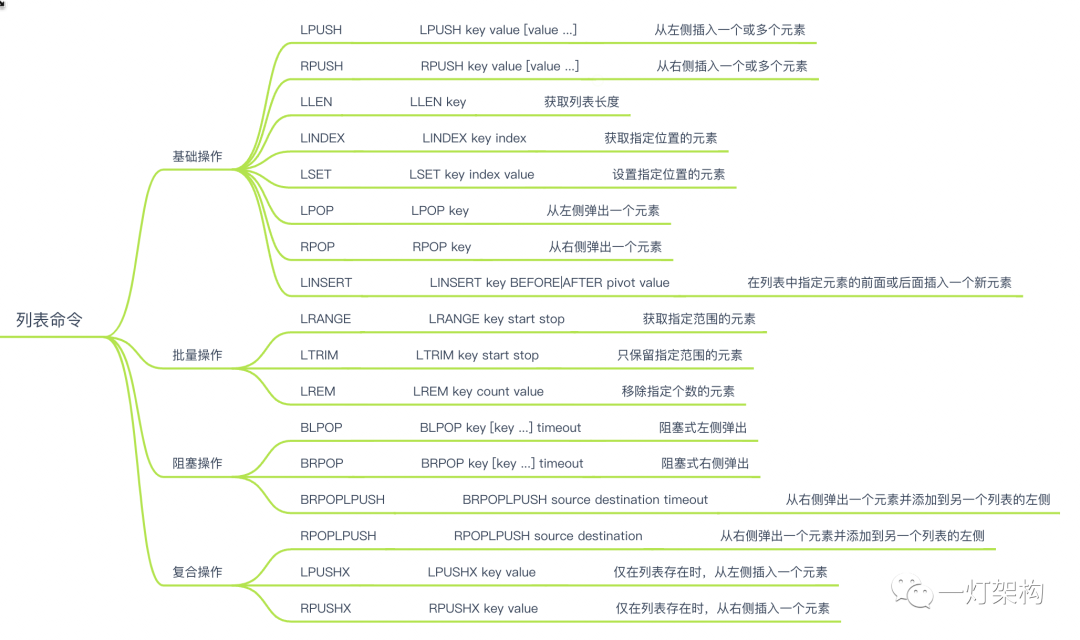
使用场景
Redis List类型由于支持在列表的头部或尾部添加元素,也支持在列表任意位置插入或删除元素,因此非常适合以下场景:
- 消息队列: Redis List类型常被用作轻量级的消息队列,生产者将消息插入队列尾部,消费者从队列头部弹出消息进行处理,可以使用LPUSH、RPUSH、BLPOP、BRPOP等命令实现。
- 时间序列: 使用Redis的LPUSH和RPUSH命令,将时间序列的数据按照时间顺序添加到列表的头部或尾部,然后使用LRANGE命令,查询一段时间范围内的数据,实现时间序列的查询。
- 排行榜: Redis List类型可以用于实现排行榜功能,将每个用户的得分作为元素值插入到列表中,使用LINSERT、LREM、LINDEX等命令进行排名操作,使用LRANGE命令查询排名前几的用户,可以使用LPUSH、LINSERT、LREM、LINDEX、LRANGE等命令实现。
- 计数器: Redis List类型可以将每个元素视为计数器的值,可以使用LPUSH、RPUSH、LINDEX、LREM等命令实现。
- 最近访问记录: Redis List类型可以用于记录最近访问的记录,将最新的访问记录插入列表头部,当列表长度超过设定的值时,使用LTRIM命令删除最旧的记录,可以使用LPUSH、LINDEX、LTRIM等命令实现。
内部编码
Redis List类型内部编码有两种,分别是ziplist和linkedlist。
ziplist
ziplist是一种特殊的编码方式,它可以将小数据量的列表存储在一个连续的内存块中,节省了内存空间,同时还可以提高存取效率。
ziplist编码的列表最大长度为2^16-1个元素,每个元素可以是字符串类型、整数类型或浮点数类型。在ziplist中,每个元素都被存储为一个字节数组,并包含一个前缀和一个后缀,用于标识该元素的类型和长度。
linkedlist
linkedlist是一种常规的双向链表结构,它可以存储任意长度的列表,并且支持高效的插入和删除操作。在linkedlist中,每个节点都包含了一个指向前一个节点和后一个节点的指针,以及一个存储元素数据的指针。
linkedlist适用于存储大数量的列表,它没有像ziplist那样的内存限制,但是会占用更多的内存空间。
Set(集合)
使用方式
Redis Set(集合)是一个无序的字符串集合,其中每个元素都是唯一的,不允许重复。Redis Set类型支持的操作包括:
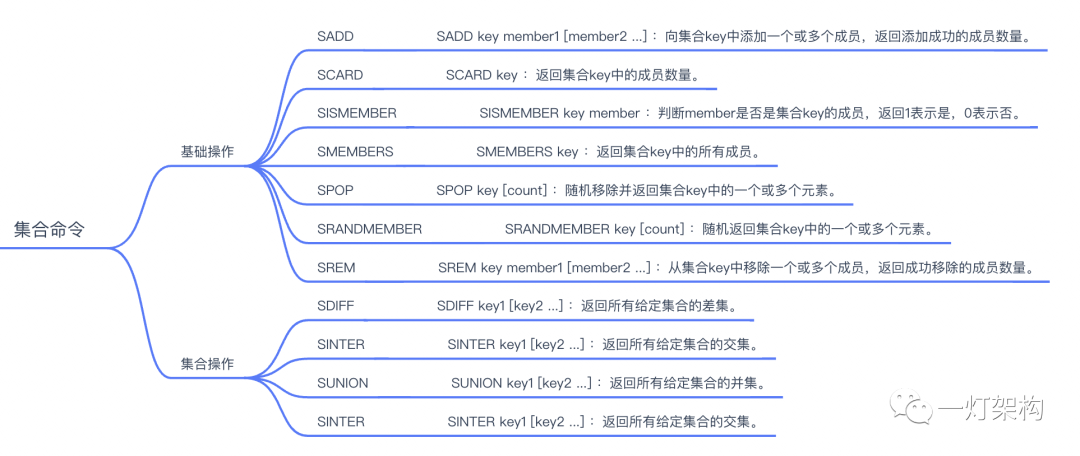
使用场景
Redis Set类型的使用场景包括:
- 标签系统:使用Set类型存储每个标签对应的对象列表,以便快速查找包含特定标签的对象。可以使用SADD、SREM、SISMEMBER、SMEMBERS等命令实现。
- 好友关系:将每个用户的好友列表作为一个集合,可以使用SADD、SREM、SISMEMBER、SDIFF、SINTER、SUNION等命令实现。
- 共同好友:使用SINTER命令计算出两个用户的共同好友,可以使用SADD、SINTER、SUNION等命令实现。
- 排名系统:将每个用户的得分作为元素值插入到集合中,使用ZADD、ZREM、ZRANK、ZSCORE等命令进行排名操作,使用ZREVRANGE命令查询排名前几的用户,可以使用ZADD、ZREM、ZRANK、ZSCORE、ZREVRANGE等命令实现。
- 订阅关系:使用Set类型存储用户订阅的内容,以便快速获取用户订阅的内容。
总的来说,Set类型适用于需要存储一组不重复的数据,并支持集合操作的场景。
内部编码
Redis Set类型的内部编码有两种:
- intset(整数集合):当Set类型只包含整数类型的数据,并且元素数量较少(小于512个)时,Redis会使用intset作为Set类型的内部编码。intset是一种紧凑的、压缩的整数集合结构,可以节省内存空间,并且支持快速的查找、插入和删除操作。在intset中,所有元素都按照从小到大的顺序排列,并且可以使用不同的编码方式(16位、32位、64位)存储不同大小范围内的整数。
- hashtable(字典):当Set类型包含字符串类型或者元素数量较多时,Redis会使用hashtable作为Set类型的内部编码。hashtable是一种基于链表的哈希表结构,可以快速地进行随机访问、插入和删除操作。在hashtable中,每个元素都被存储为一个字符串,并且使用哈希函数将字符串映射到一个桶中,然后在桶中进行查找、插入和删除操作。
在实际使用中,当Set类型的元素全部为整数类型时,建议使用intset编码;而当Set类型的元素包含非整数类型时,才使用hashtable编码。
Zset(有序集合)
使用方式
Redis中的Zset(有序集合)是一个键值对集合,其中每个元素都关联一个分值(score),通过分值进行排序,可以看作是一个字典(dict)和一个跳跃列表(skip list)的混合体,它可以存储多个相同的元素,但每个元素必须有一个唯一的score值。
支持的操作包括:

使用场景
Redis Zset是一种有序集合,其使用场景主要包括以下几个方面:
- 排行榜:使用Zset类型可以实现排行榜功能,将每个用户的得分作为元素值插入到集合中,使用ZADD、ZINCRBY、ZREM等命令进行排名操作,使用ZRANGE、ZREVRANGE命令查询排名前几的用户。
- 最近访问记录:使用Zset类型可以用于记录最近访问的记录,将最新的访问记录插入集合中,使用ZREMRANGEBYRANK命令删除最旧的记录,使用ZRANGE命令查询最近访问的记录。
- 计数器:Redis Zset可以用于实现计数器功能,比如统计某个页面的访问次数、统计某个广告的点击量等。将页面ID或广告ID作为成员(member)存储在Zset中,以访问次数或点击量作为分数(score)存储。
- 好友关系:Redis Zset可以用于存储用户之间的关注关系以及用户之间的互动,比如点赞、评论等。可以将用户ID作为成员(member)存储在Zset中,将时间戳或者其他标识作为分数(score)存储,以此记录用户之间的互动情况。
内部编码
Redis Zset的内部编码有两种:
- ziplist编码:当Zset中元素个数小于128个,并且所有元素的长度都小于64字节时,Redis会使用ziplist编码存储Zset。这种编码方式可以节省内存空间,并且可以提高存取效率,但是不支持随机访问和范围查询。
- skiplist编码:当Zset中元素个数大于等于128个,或者有一个元素的长度大于64字节时,Redis会使用skiplist编码存储Zset。这种编码方式支持高效的随机访问和范围查询,但是需要占用更多的内存空间。
Geo(地理位置)
使用方式
Redis Geo(地理位置)是一个键值对集合,其中每个元素都包含一个经度和纬度,可以用于存储地理位置信息并支持基于位置的搜索。Redis Geo支持的操作包括:

Redis Geo类型适用于需要存储地理位置信息并支持基于位置的搜索的场景,比如附近的人、附近的商家等。
使用场景
Redis Geo类型的使用场景如下:
- 位置服务:用于存储地理位置信息,如餐厅、商店、机场、医院等的经纬度信息,可以通过 Geo 库提供的命令查询指定范围内的所有商家信息。
- 车辆监控:用于车辆位置跟踪和监控,可以将车辆的经纬度信息存储在 Redis 中,并通过 Geo 库提供的命令查询车辆的位置,以及在指定半径内的其他车辆信息。
- 物流配送:用于存储配送员的位置信息,以及需要配送的订单信息的经纬度信息,可以通过 Geo 库提供的命令查询配送员在指定范围内的订单信息,以提高配送效率。
- 电商推荐:用于存储用户的位置信息,以及商家和商品的经纬度信息,可以通过 Geo 库提供的命令查询指定范围内的商家和商品信息,以提供更加精准的推荐服务。
- 游戏地图:用于存储游戏地图的位置信息和玩家的位置信息,可以通过 Geo 库提供的命令查询玩家在游戏地图上的位置,以及在指定半径内的其他玩家信息,以提供更加丰富的游戏体验。
- 社交应用:用于存储用户的位置信息,以及附近的其他用户的位置信息,可以通过 Geo 库提供的命令查询指定范围内的用户信息,以提供更加精准的社交服务。
内部编码
Redis Geo类型内部使用zset来存储地理位置信息,其中元素的score值为经度,member值为经纬度组合的字符串。在使用GEORADIUS和GEORADIUSBYMEMBER命令搜索元素时,Redis会构建一个跳跃表,以实现高效的搜索。
HyperLogLog(基数统计)
使用方式
Redis HyperLogLog(基数统计)是一种基于概率统计的数据结构,用于估计大型数据集合的基数(不重复元素的数量),以及对多个集合进行并、交运算等。HyperLogLog的优点是可以使用极少的内存空间,同时可以保证较高的准确性。
每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。

使用场景
HyperLogLog的使用场景主要包括以下几个方面:
- 用户去重:使用HyperLogLog可以对海量的用户数据进行去重,快速地统计出不重复的用户数量。
- 网站UV统计:使用HyperLogLog可以对网站的访问日志进行分析,统计出每天、每周、每月的独立访客数量。
- 广告点击统计:使用HyperLogLog可以对广告的点击数据进行分析,统计出独立点击用户的数量,以及对多个广告进行并、交运算等。
- 数据库查询优化:使用HyperLogLog可以对数据库中的数据进行去重,减少查询的数据量,提高查询效率。
- 分布式计算:使用HyperLogLog可以在分布式系统中对数据进行去重、并、交等操作,以支持分布式计算。
使用HyperLogLog可以大大减少内存占用和计算时间,是处理大数据量去重计数的有效工具。
内部编码
Redis HyperLogLog类型的内部编码使用的"稀疏矩阵"和”稠密矩阵“。
当计数较少时,采用”稀疏矩阵“,其中绝大部分元素都是0。计数增多后,超过阈值后,会转换成”稠密矩阵“。
Bitmaps(位图)
使用方式
Redis Bitmaps(位图)是一种紧凑的数据结构,可以用于表示一个只有0和1的数组。位图可以用于高效地存储大规模的布尔值,以及进行位运算、位图图形化等操作。Redis Bitmaps支持的操作包括:

使用场景
Redis Bitmaps适用于需要高效地存储大规模的布尔值,并进行位运算、统计等操作的场景。比如:
- 统计在线用户数:使用Bitmaps类型来表示用户的在线状态,例如一个bit位表示一个用户,当用户登录时将对应的bit位置为1,当用户退出时将其位置为0。这样可以非常方便地进行在线用户的统计。
- 黑白名单统计:在网络安全中,可以使用位图记录IP地址的访问情况、黑白名单等信息。
- 统计用户访问行为:例如将每个页面或功能点表示为一个bit位,用户访问时将对应的bit位置为1,未访问则为0。这样就可以方便地统计用户的访问习惯,了解用户对产品的喜好和热点等信息。
- 布隆过滤器:这是最常用的场景,布隆过滤器是一种用于快速判断某个元素是否在集合中的算法,在大数据量场景下其效率非常高。Redis的Bitmaps类型可以用来实现布隆过滤器,节约存储空间,并提高查询效率。
内部编码
Redis Bitmaps类型的内部编码使用了一种称为“压缩位图”的数据结构。它通过使用两个数组来存储位图数据:一个存储实际位的值,另一个存储每个字节中1的个数。这种编码方式可以大大压缩位图数据的大小。
Stream
介绍
Redis Stream 是 Redis 5.0 版本新增加的数据类型,Redis 专门为消息队列设计的数据类型。
在 Redis 5.0 Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
- 发布订阅模式,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息的缺陷;
- List 实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一 ID。
基于以上问题,Redis 5.0 便推出了 Stream 类型也是此版本最重要的功能,用于完美地实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。
常见命令
Stream 消息队列操作命令:
- XADD:插入消息,保证有序,可以自动生成全局唯一 ID;
- XLEN :查询消息长度;
- XREAD:用于读取消息,可以按 ID 读取数据;
- XDEL : 根据消息 ID 删除消息;
- DEL :删除整个 Stream;
- XRANGE :读取区间消息
- XREADGROUP:按消费组形式读取消息;
- XPENDING 和 XACK:
- XPENDING 命令可以用来查询每个消费组内所有消费者「已读取、但尚未确认」的消息;
- XACK 命令用于向消息队列确认消息处理已完成;
问题
Redis Stream 消息会丢失吗?
使用一个消息队列,其实就分为三大块:生产者、队列中间件、消费者,所以要保证消息就是保证三个环节都不能丢失数据。

Redis Stream 消息队列能不能保证三个环节都不丢失数据?
- Redis 生产者会不会丢消息?生产者会不会丢消息,取决于生产者对于异常情况的处理是否合理。 从消息被生产出来,然后提交给 MQ 的过程中,只要能正常收到 ( MQ 中间件) 的 ack 确认响应,就表示发送成功,所以只要处理好返回值和异常,如果返回异常则进行消息重发,那么这个阶段是不会出现消息丢失的。
- Redis 消费者会不会丢消息?不会,因为 Stream ( MQ 中间件)会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,但是未被确认的消息。消费者可以在重启后,用 XPENDING 命令查看已读取、但尚未确认处理完成的消息。等到消费者执行完业务逻辑后,再发送消费确认 XACK 命令,也能保证消息的不丢失。
- Redis 消息中间件会不会丢消息?会,Redis 在以下 2 个场景下,都会导致数据丢失:
- AOF 持久化配置为每秒写盘,但这个写盘过程是异步的,Redis 宕机时会存在数据丢失的可能
- 主从复制也是异步的,主从切换时,也存在丢失数据的可能 (opens new window)。
可以看到,Redis 在队列中间件环节无法保证消息不丢。像 RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时是部署一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,也就是有多个副本,这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。
Redis Stream 消息可堆积吗?
Redis 的数据都存储在内存中,这就意味着一旦发生消息积压,则会导致 Redis 的内存持续增长,如果超过机器内存上限,就会面临被 OOM 的风险。
所以 Redis 的 Stream 提供了可以指定队列最大长度的功能,就是为了避免这种情况发生。
当指定队列最大长度时,队列长度超过上限后,旧消息会被删除,只保留固定长度的新消息。这么来看,Stream 在消息积压时,如果指定了最大长度,还是有可能丢失消息的。
但 Kafka、RabbitMQ 专业的消息队列它们的数据都是存储在磁盘上,当消息积压时,无非就是多占用一些磁盘空间。
因此,把 Redis 当作队列来使用时,会面临的 2 个问题:
- Redis 本身可能会丢数据;
- 面对消息挤压,内存资源会紧张;
所以,能不能将 Redis 作为消息队列来使用,关键看你的业务场景:
- 如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。
- 如果你的业务有海量消息,消息积压的概率比较大,并且不能接受数据丢失,那么还是用专业的消息队列中间件吧。
补充:Redis 发布/订阅机制为什么不可以作为消息队列?
发布订阅机制存在以下缺点,都是跟丢失数据有关:
- 发布/订阅机制没有基于任何数据类型实现,所以不具备「数据持久化」的能力,也就是发布/订阅机制的相关操作,不会写入到 RDB 和 AOF 中,当 Redis 宕机重启,发布/订阅机制的数据也会全部丢失。
- 发布订阅模式是“发后既忘”的工作模式,如果有订阅者离线重连之后不能消费之前的历史消息。
- 当消费端有一定的消息积压时,也就是生产者发送的消息,消费者消费不过来时,如果超过 32M 或者是 60s 内持续保持在 8M 以上,消费端会被强行断开,这个参数是在配置文件中设置的,默认值是
client-output-buffer-limit pubsub 32mb 8mb 60。