分布式ID方案
为什么需要全局唯一ID
传统的单体架构的时候,我们基本是单库然后业务单表的结构。每个业务表的ID一般我们都是从1增,通过AUTO_INCREMENT=1设置自增起始值,但是在分布式服务架构模式下分库分表的设计,使得多个库或多个表存储相同的业务数据。这种情况根据数据库的自增ID就会产生相同ID的情况,不能保证主键的唯一性。
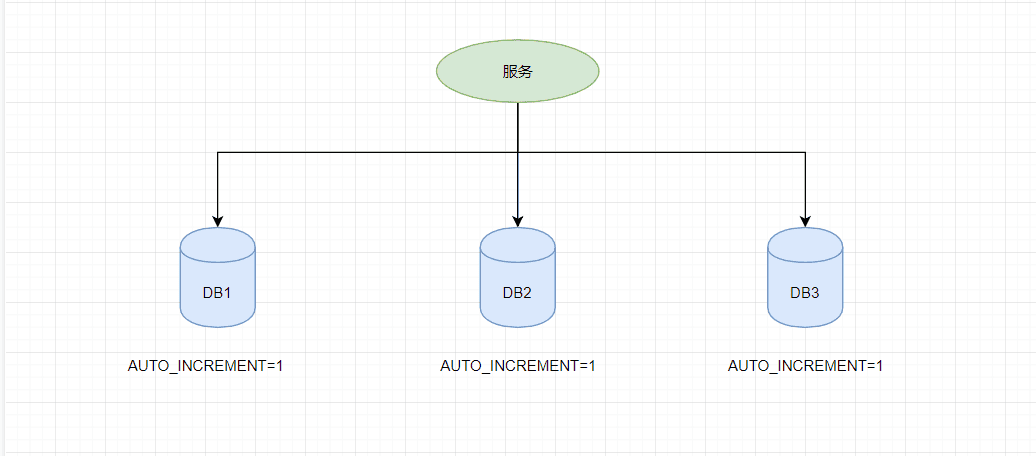
如上图,如果第一个订单存储在 DB1 上则订单 ID 为1,当一个新订单又入库了存储在 DB2 上订单 ID 也为1。我们系统的架构虽然是分布式的,但是在用户层应是无感知的,重复的订单主键显而易见是不被允许的。那么针对分布式系统如何做到主键唯一性呢?
UUID
UUID (Universally Unique Identifier),通用唯一识别码的缩写。UUID是由一组32位数的16进制数字所构成,所以UUID理论上的总数为 16^32=2^128,约等于 3.4 x 10^38。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
生成的UUID是由 8-4-4-4-12格式的数据组成,其中32个字符和4个连字符' - ',一般我们使用的时候会将连字符删除 uuid.toString().replaceAll("-","")。
目前UUID的产生方式有5种版本,每个版本的算法不同,应用范围也不同。
基于时间的UUID- 版本1: 这个一般是通过当前时间,随机数,和本地Mac地址来计算出来,可以通过 org.apache.logging.log4j.core.util包中的 UuidUtil.getTimeBasedUuid()来使用或者其他包中工具。由于使用了MAC地址,因此能够确保唯一性,但是同时也暴露了MAC地址,私密性不够好。DCE安全的UUID- 版本2 DCE(Distributed Computing Environment)安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。这个版本的UUID在实际中较少用到。基于名字的UUID(MD5)- 版本3 基于名字的UUID通过计算名字和名字空间的MD5散列值得到。这个版本的UUID保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。随机UUID- 版本4 根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但是重复的可能性可以忽略不计,因此该版本也是被经常使用的版本。JDK中使用的就是这个版本。基于名字的UUID(SHA1)- 版本5 和基于名字的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法。
虽然 UUID 生成方便,本地生成没有网络消耗,但是使用起来也有一些缺点,
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,暴露使用者的位置。
- 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能
中间层
从为什么需要全局唯一ID里面可知,是因为获取ID的源从以前的一个变成了多个,所以才会导致重复,那我们只需要做一个公共的获取ID的中间层就可以了,像利用公共的Mqsql、公共的Redis、公共的MongoDB、公共的ID生成服务组件都是这样的道理。总的来说有三种方案:
单纯递增
比如:Mysql的自增、redis的INCR、mongoDB的自增等,优点是简单易实现,缺点是竞争过大、吞吐量低、可用性差
步长递增
以Mysql举例,假设现在根据业务分了4个库了,代表有4个表,分别是T1、T2、T3、T4,我们设置它们的起始值为1,2,3,4,步长为4,那它们id则为下所示
T1:1,5,9,13,17
T2:2,6,10,14,18
T3:3,7,11,15,19
T4:4,8,12,16,20
可见一样也不会重复,优点是打破单调递增的局限、性能相比较好,缺点不利于拓展,特殊情况可能会导致重复
号段模式
同样以Mysql为例,以上ID都是一个一个的分发,自然导致了并发可能过大的问题,此模式就是为了降低对中间层的访问次数,一次性发放一批ID给客户端缓存,用完了在重新获取,这就是这模式的核心思想,具体以实际为准
雪花算法-Snowflake
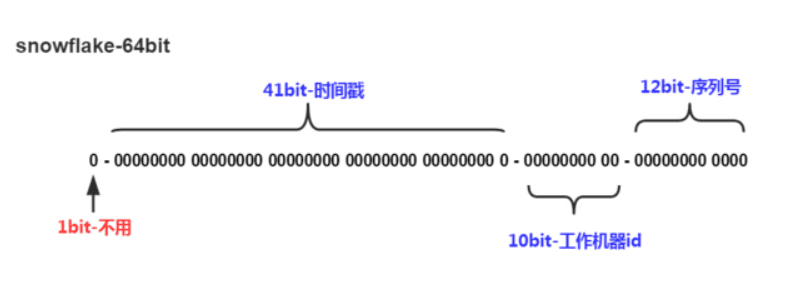
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。而 Java中64bit的整数是Long类型,所以在 Java 中 SnowFlake 算法生成的 ID 就是 long 来存储的。
- 第1位占用1bit,其值始终是0,可看做是符号位不使用。
- 第2位开始的41位是时间戳,41-bit位可表示2^41个数,每个数代表毫秒,那么雪花算法可用的时间年限是
(1L<<41)/(1000L360024*365)=69 年的时间。 - 中间的10-bit位可表示机器数,即2^10 = 1024台机器,但是一般情况下我们不会部署这么台机器。如果我们对IDC(互联网数据中心)有需求,还可以将 10-bit 分 5-bit 给 IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,具体的划分可以根据自身需求定义。
- 最后12-bit位是自增序列,可表示2^12 = 4096个数。
这样的划分之后相当于在一毫秒一个数据中心的一台机器上可产生4096个有序的不重复的ID。但是我们 IDC 和机器数肯定不止一个,所以毫秒内能生成的有序ID数是翻倍的。
雪花算法提供了一个很好的设计思想,雪花算法生成的ID是趋势递增,不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的,而且可以根据自身业务特性分配bit位,非常灵活。
但是雪花算法强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。如果恰巧回退前生成过一些ID,而时间回退后,生成的ID就有可能重复。官方对于此并没有给出解决方案,而是简单的抛错处理,这样会造成在时间被追回之前的这段时间服务不可用。并发足够大的情况下,ID会用完,因为自增序列会达到上限
总结
以上每种模式都有自己的缺点,实际上大多是以上几种模式的结合来运用的,比如美团的Leaf、百度的UidGenerator,所以大方向是两个方案:
- 综合后的缓存+号段
- 雪花的改良,天然的唯一性
如何解决时钟回拨问题
时钟回拨:指的是系统时钟被向后调整到之前的时间,也就是在某一瞬间,系统时间突然跳回到之前的某个时间点;
这对雪花来说无疑是致命!
这个问题谈不上解决,只能说规避或者保证唯一的解决方案:
拒绝策略
这个很简单,就是检测到时钟回拨后,拒绝ID的生成
使用物理时钟和逻辑时钟结合的方式
物理时钟是指系统硬件上的时钟,它具有不同步的风险。而逻辑时钟则是指根据本地时钟和网络时间协议(NTP)获取的网络时钟计算出来的时间戳,它具有更好的同步性能。
在使用逻辑时钟时,可以将本地的逻辑时钟与 NTP 服务提供的时间进行比较,并使用两个时钟之间的差值来确定当前的本地时间。如果本地时钟发生回拨,可以通过记录回拨的信息以及处理回拨前后的时间变化来避免ID重复或生成失败。
时间后移消费
每次产生ID的时候保存一次时间,发生时间回拨的时候,取出缓存的时间+1s,缺点是时间可能会错位